Standards for the Social Web
Introduction
Many of the systems discussed in the previous chapter have proven foundational for ongoing efforts to create standards for decentralised social interactions on the Web. Previously we gave an overview of the standards being produced by the W3C Social Web Working Group; now we discuss in more depth notable decisions and debates of the group, describe the resulting standards in more detail, and outline how to actually go about building decentralised social systems which empower self-presentation using these standards. The contributions of this chapter are as follows:
- A critical analysis of contemporary standards for decentralised social interaction on the Web, taking into account social dynamics of collaborative projects and the W3C consensus model, as well as the technical considerations.
- A characterisation of the problems being solved by the Social Web WG, and how these relate to the more specific problem of online self-presentation, by means of the conceptual framework from chapter 3.
- A technical primer for the work produced by the group (published by the W3C as a Working Group Note: Social Web Protocols).
- Prototype implementations of standards produced by the group, and a report on their interoperability with implementations produced by others.
This chapter brings together the qualitative research from earlier with concrete technical outcomes in the form of protocol designs. The work of the Social Web Working Group is in effect a case study for designing decentralised Social Web systems, but what is presented here is more than a survey or observational study. Since I was first a member of the Working Group, and then the W3C Team Contact, I was immersed in every part of the decision making and contributed in some form to all of the specifications produced. The Social Web Protocols document contributes a deeper understanding of the various protocols, and importantly how they can complement or contradict each other. This document is particularly useful because of the complicated social dynamics of the group, and produced as an introductory piece for developers entering this space anew. Technical decisions that have been made by the Working Group over the past (almost) three years were not made in a vacuum, nor dictated by cold logic, but rarely backed up with truly meaningful data. Most decisions were made on the - admittedly well-honed - gut instinct of experts, data from small samples, and anecdotal evidence. The specifications that resulted were influenced by this, so it is important to examine the development processes. Social Web Protocols contains fine technical details of the Working Group's recommendations, which are important for a complete picture and analysis of the current cutting-edge of decentralised Social Web standards. An overview of Social Web Protocols is presented in this section, and the specifics can be found in Appendix SWP.
Personal data and self-presentation
Standards aren't really all that interesting until they're implemented and used. This section describes a single-user system, a personal social datastore, built around some of the protocols designed by the Social Web Working Group. I continually used and improved this system for over two years, as the core of my online presence and a public log of various digital and physical activities. I reflect upon the impact that doing so has had on me at a personal level, because in designing personal datastores and decentralised social systems we are encouraging this type of behaviour, and I believe as developers and system designers, we should experience it first-hand.
Further, in a decentralised Social Web, we cannot assume any kind of consistency between nodes in a network. Everyone's experience of the technology through which interactions are mediated may be completely different. I use my own experience with a personal social datastore to discuss how and why we need to take this into consideration when observing and understanding peoples' behaviour in future online social networks. To faciliate this discussion, I use the concept of a Web Observatory.
A Web Observatory is a system which gathers and links to data on the Web in order to answer questions about the Web, the users of the Web and the way that each affects the other. - webscience.org
This section has been adapted from work published as Observing the Decentralised Social Web (one telescope at a time) (2016, Proceedings of WWW, Perth).
Introduction
Studying communities through passive and active digital traces, as Web Observatories are designed to do [webobs, websciobs], brings with it a host of privacy, ethical, and methodological concerns. Attempts to address online privacy issues in general are being made with a push towards re-decentralising the Web [dcent], in part through open Web standards and work on promoting personal data stores as alternatives to centralised or third-party services. Using this momentum can benefit the Web Science community as well as their observees (though it brings with it its own set of challenges). Decentralisation is applied to Web Observatories in particular through the idea of a Personal Web Observatory [vk14] as a user-controlled (as opposed to third-party imposed) means of collecting and tracking data.
I believe that the perspectives of both subject and experimenter are valuable when it comes to studying people in new ways. Taking inspiration from the reflective practices of the Quantified Self community, I progressively built features into my own personal website which allow monitoring and visualisation of day-to-day aspects of my life, and used it continuously for the period of two years and counting. Immersion in the ongoing effects of self-tracking in a decentralised manner led to greater insight in working towards Personal Web Observatories than either developing a personal data store or engaging in self-tracking through third-party services could do alone.
This section begins by outlining related work on Web Observatories and Quantified Self. It includes a summary of the architecture of the personal data store being studied, and the types of data collected. I discuss the results in terms of psychological impact of the experiment, evolving motivations, and expected and unexpected consequences. In conclusion I relate these results to new and existing challenges for Web Observatories and Web Scientists who want to study data generated by Personal Web Observatories or similarly decentralised systems.
Background
Personal Web Observatories
Web Observatories concern the use of peoples' digital footprints as the subject of academic inquiry [webobs, websciobs]. Such data encompasses all manner of online and offline activities, and it may be collected passively by systems with which individuals interact, or actively logged, or some combination of the two. In order to address negative privacy implications of collecting and analysing this data, [vk14] introduces the idea of a Personal Web Observatory. Personal data stores are presented as an architecture for a decentralised Web Observatory, to allow individuals to maintain control over their data whilst still participating in scientific studies or otherwise releasing their data for use by third parties.
A Personal Web Observatory relies on individuals opting in to self-tracking activities; connecting their personal data store to sensors or user interfaces.
Self-tracking and Quantified Self
There have been a small number of high profile instances of individuals collecting a large volume of data about themselves, then offering it up for auction [slate, wired]. Even more common are those who track data about themselves in order to: orchestrate behavioural changes; monitor bodily functions; learn new things about themselves; discern cause-and-effect relations; aid memory; manage information and life events; make better decisions; or just for the fun of it (for surveys of self-tracking motivations and tools, see [reflect, sleep, motivations, bigdata]). This personal self-tracking is disruptive to traditional notions of big data and data science [bigdata].
The Quantified Self (QS) community is large, global, and growing. In-person conferences and meetups are held regularly [darkside, eleven]. Whilst they use a wide range and combination of DIY and off-the-shelf devices for self-tracking [eleven, swan12], what is particularly interesting are their reflective practices. QS practitioners engage in creative ways to collect, visualise, and understand data about themselves. At meetups, talks are focussed around deep personal insights, optimisation and improvement, and active self-awareness, rather than technology or tools [sleep, swan12, eleven].
However, the psychological impact of quantifying day-to-day activities is more complex than detecting trends and setting goals. Self-tracking may work against our best interests as interpretation of data is both subjective, and prone to re-interpretation at each viewing. There is also evidence that attempting to enforce a particular behaviour can have the opposite effect. Peoples' memories and impressions are easily influenced by external and internal factors [irony]. A participant in [reflect] expressed concern about becoming "compulsive" about data collection, and [reflect] also describes how many off-the-shelf self-tracking services do not provide adequate means to aid user reflection.
Another negative effect of QS tracking is poor security of sensor software and third-party storage which can compromise individuals' data [symantec]. Plus, using third-party software typically comes with terms of service which are problematic from a privacy perspective.
Quantified self tracking is gamification of non-play activities, and [gaming] describes gamification as having surveillance at its root. [gaming] emphasises that quantification is a tool for governance and control and [eleven] concurs that statistics are historically used to manage populations, and this form of control is internalised by individuals for management of self. Prevalence of QS devices and habits can serve to normalise surveillance. Further, QS tracking in the workplace is being introduced in ways that are becoming increasingly difficult to opt-out of, and raises unrealistic expectations of workers "fostered by a quantified, machine-like image of human productivity" [moore16].
Nonetheless, [eleven] describes QS participants who pushing back against the expectations and categories of the companies whose devices they use with their own interpretations of their data, "calling into question who gets to do the aggregation and how".
Building a Personal Web Observatory
In this section I describe my Personal Web Observatory setup. One notable constraint from the outset was that in order to minimise maintenance requirements the system needed to be no more complicated to run than a personal website (setup and maintenance being a concern called out in [vk14]). As such it is implemented in PHP and runs on standard shared Web hosting, with a MySQL backend.
Architecture
The system (which is named sloph) constitutes a central database which is an RDF quadstore (layered on top of a MySQL database by the ARC2 PHP library). Using a graph data model facilitates the addition of new data without the overhead of updating schema or models in the core code.
For incoming data, it uses two endpoints: publication and notification, which implement the server portions of ActivityPub and LDN respectively. To compensate for overlapping standards, the publication endpoint additionally includes bridging code which converts Micropub requests in ActivityPub requests before proceeding, and the notification endpoint converts Webmentions into LDN. Data is processed to examine its validity, and stored as-is in the quad store. Publication data all uses the AS2 syntax and vocabulary (or extensions thereof), and notification data is stored using whatever vocabulary is sent by the notifying party. Data from each endpoint are stored in different graphs in the quad store to manage provenance.
The notifications endpoint can receive unsolicted messages from any LDN Sender, which may be somebody else's personal data store, or a clientside tool. In addition, some third-party services have been configured to send notifications to the notification endpoint. Webmention.io and GitHub have webhook settings, which are set to the notifications endpoint. They forward JSON data, which is easily convertible into JSON-LD, used by the LDN standard. Brid.gy is a service which runs in the background and monitors my social media profiles for replies to my posts, then sends these as Webmention notifications. Upon certain new incoming notifications, the endpoint sends a request to the PushOver API, which sends a push notification to my Android phone.
Data may be retrieved as individual items (AS2 Objects or Activities), or in sets (AS2 Collections); all are identified by URLs. Content negotiation is employed so that requesting clients may access the data in any desired RDF syntax, or HTML. For HTML display, simple templates are created for each 'type' (or shared between a set of similar types) of data item. It is expected that most requests come from Web browsers, so the HTML content is delivered most often. However, other applications or services may consume the data, including readers (which may mix together multiple streams of data for the user), aggregators (which read the data and perform some manipulation or calculation over it to display the results) or publishing clients (which offer editing or combining of existing data). All data is public; I did not implement access control.
The publication endpoint performs additional functions for data enhancement and distribution. It automatically adds missing metadata to posts if necessary (for example, published date and author), as well as storing new relations between posts and relevant collections such as tags, as well as the specific collections required by ActivityPub. The publication endpoint forwards text posts to Twitter, if necessary truncating them and adding a link back to the original, which helps with reach of content (since I don't yet have a subscription mechanism implemented). The publication endpoint also scans the content and certain attributes of incoming data for URLs, and behaves as an LDN and Webmention Sender to deliver notifications to others, if possible.

Data
[vk14] suggests that the first feature of a PWO should be to allow individuals to consolidate data collected by third parties into one repository under their control. Rather than attempting to aggregate - or even find - all data about myself spread across the Web, I chose a handful of services which have particular value to me, that I have been using to actively log particular things. I exported data from Lastfm (over ten years of music listening history), Twitter (7 years of short notes), Runkeeper (1 year of runs, walks and hikes with GPS traces), and Github and Bitbucket (5 years of code commit history), and Firefox bookmarks (2 years). I also exported data from 750words.com (almost 7 years of intermittent use) but did not import this into my store due to private content and no reliable access control built in.
On top of these data dumps I created the following templates:
| Type of data | Attributes displayed * |
|---|---|
| Articles (blog posts) | name, content |
| Short notes (like Tweets) | content |
| Meals logged | description, restaurant if applicable |
| Travel plans | start and end location (map), date and time, means of transport, cost |
| Checkins to specific places | location (map) |
| Checkins to categories of place, aka 'vague' checkins (eg. 'home', 'office') | location, duration of time there, associated colour |
| Likes | URL of thing liked |
| Bookmarks | URL of bookmark, name of bookmark, optional comment or quote |
| Reposts (aka shares aka retweets aka reblogs) | URL of post, optional comment |
| Acquisitions (purchases and free stuff) | description, source, cost, photo |
| Additions to photo albums | photos and URL of album |
| Events and RSVPs | location, date and time, name, description, event website |
| Subscriptons / follows | URL of profile followed |
| Sleep times | start and end date and time, optional comment |
| * All posts contain tags and a published date, and may contain a last modified date. | |
Templates were created not all at once, but as I decided to start tracking something new and wanted to visualise it. Templates were continually modified and improved over the course of the year.
At the time of writing, I display posts in three different formats on my homepage (figure 19): a feed of the most recent eight article and note posts displayed in full; a list of the most recent of each type of post, displayed as a sentence (eg. "the last thing I ate was toast with peanut butter, 25 minutes ago"); and the last 1600 posts of all kinds, visualised as a string of small coloured boxes with icons. The colours represent where I was at the time of making the post (according to the most recent prior 'vague' checkin) and the icons indicate the type of post. Clicking on any of these boxes takes you to the post itself. In addition, the background colour of the homepage changes according to where I am at the present time. I also show my top 128 tags, and the number of posts for each.
Another type of output is a /summary page, which aggregates data between any two dates, defaulting to the past seven days. This is useful for producing a year- and week-in-review, and includes total amount of money spent, top foods eaten, number of words written, and various averages.
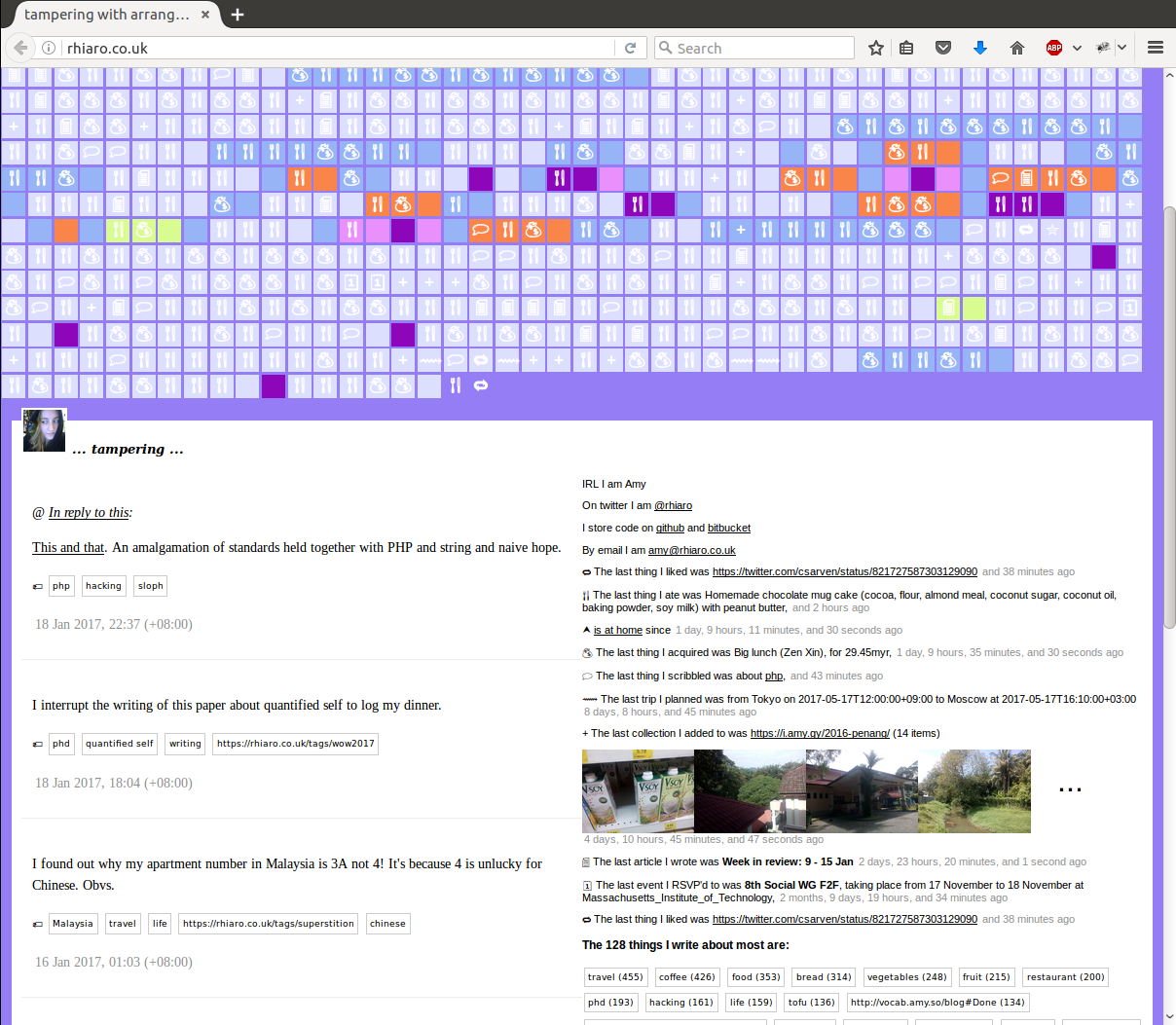
Using a Personal Web Observatory
Recording data
All data is actively recorded; that is, I enter all of the data and no posts are triggered by some other process or sensor. Unfortunately, for the sources of data exported from other services mentioned previously, I did not (yet) implement a connection to their various APIs to post subsequent data directly to my site.
As I decided to log a new kind of data, I either created or sought out a suitable client. As an intermediary measure (eg. while a client was in development), I could insert data into the quadstore directly using my SPARQL endpoint, which turns out to be a pretty useful bootstrapping measure. Clients I developed myself are simple web forms, which post AS2 data as JSON-LD to my publication endpoint.
I typically logged data at the time of its occurrence if possible. If I didn't have an internet connection (a frequent occurrence whilst traveling) I used a local 'timestamp' Android app to record the time and note crucial details, then back-dated posts at the earliest opportunity.
Practical uses for small data
[vk14] proposes that "small data analytics, while sparse, could be made statistically viable when gathered longitudinally over time." Whilst I haven't done any complex statistical analysis on my data, certainly aggregated results, counts, and some calculations of means have been personally insightful. To take some trivial examples: that I drank on average 0.8 cups of coffee per day in 2016 was lower than I expected; that I spent an average of $28.71 per day was higher than I expected; and that I spent 1 month, 15 days, 6 hours, 41 minutes, and 15 seconds travelling between places is just kind of interesting (and something I particularly wanted to find out when I started recording 'vague' checkins). I don't expect these statistics to be remotely captivating for anyone else; such is the value of personal "small data."
Such aggregations were able to be put to more focused uses. Logging all of my purchases did not raise my internal awareness of how much I was spending on a weekly or monthly basis, but when I realised I wasn't saving money after about six months it was trival to write a small web app which consumed my data stream, aggregated the total cost by certain categories, and displayed the amount I spent in any given month or week. Adding a setting for a monthly budget goal let the app send me notifications to stop spending when it noticed I was on track to exceed this in the current week. The app is not coupled to my personal site or data, so it can be used by anyone who publishes a stream of their purchases using AS2.
An initial motivation of recording 'vague' checkins was so people could check my site to see whether I was on my way if we were planning to meet, or if I shouldn't be disturbed (eg. if I was in a meeting). Industrious computer science friends created an IRC bot that consumed my /where endpoint and responded when asked $whereis rhiaro. Other users of the same IRC channel added their own location reporting endpoints for the bot to read, some down to GPS accuracy with a map, shortly thereafter. Other unanticipated uses of data I was recording include launching a travel blog which filtered travel-related posts and photos from my main feed, and a food blog which includes my food logs, food-related photos, and any posts or bookmarks about recipes or restaurant reviews.
If my website is down, I do not exist
Having visible output for each log on my website motivated me to keep logging. I am missing lots of checkins to specific cities because I had trouble with a maps API and didn't complete the template to display them. Similarly I never got around to creating a compelling view of sleep records, so logs for those are few and far between.
I felt an internal pressure to ensure my data stream was complete. If I was offline or out of battery for a length of time, I would keep logs on paper to back-date later. This was due both to wanting to ensure aggregate data was accurate, and fear of 'losing' associated memories. Relatedly, I looked (and in fact still do) through historical logs with surprising frequency, and found memories of events, people and places were triggered by descriptions of meals or photos of purchases that I might otherwise have forgotten. I worry that this is unhealthy, boarding on obsessive behaviour though. At times, particularly before I had a streamlined offline-logging plan in place, or if it was socially inappropriate to be writing or typing logs, I felt anxious that I would neglect to log something.
When my webhost experienced outages, leaving me unable to record data, I both noticed far more quickly and felt a far stronger personal impact than I previously would have when my site was mostly static and for infrequent blogging. I complained to my hosting provider more frequently, and projected a sense of urgency that was probably disproportionate. I was left with a feeling of if my website is down, I do not exist, and I found myself wondering if sysadmins in a data center the other side of the world could possibly know or care about the anxiety they were causing me.
Other, predicted, psychological impact was that publicly logging photos of all of my purchases made me more conscious about what I bought. Even though I didn't actually think anyone looked at my feed, I found being aware that someone could see it helped me to, for example, resist buying junk food at the supermarket.
Discussion
In this section I expand on some of the topics raised by the results of my creation and use of a PWO, and in particular the implications for Web Observatories, and Web Science as a whole. I think these results highlight many open questions and future research challenges.
PWOs are at the intersection of Web Observatories and Personal Data Stores. Research on the former is concerned with passively collecting and analysing how individuals and communities already use the Web, in order to learn about society. Research on the latter is concerned with improving and often actively influencing the lives of individuals. When we think about integrating individual data stores into an architecture for mass observation, we need to find a way to account for the conflicts that arise.
Technical considerations
People are likely to be discouraged from using a PWO if it comes with a high burden of maintenance or cost of running [vk14]. I was able to minimise the impact of this on myself by integrating it into a system I was already maintaining (my personal website). Doing this had a significant impact on the technologies I was able to use, which was in some ways restricting, but beneficial in the long term. Shared Web hosting, PHP and MySQL are widespread and well-supported; this demonstrates that a PWO need not be architected around specialist or niche technologies, and need not be difficult or burdensome to set up and use. Certainly lowering the barrier to entry to people who already run their own websites could help to springboard adoption.
Centralised services are frequently bought out, shut down, or change focus or terms of service. Whilst the technical burden of maintaining ones own personal data store may be higher than delegating this to a third-party comes with different, but not insubstantial, risks.
Serious review of common practices and formal Web standards can smooth the path to interoperability between different instances of WOs and PWOs. Though the standards discussed in this article were designed from a decentralised Social Web perspective rather than a Web Observatories one, the overlap is clear. Implicit self-tracking that makes up a part of ordinary social media use can be supported in the move towards decentralisation, and privacy-preserving PWOs may start to exist as a side-effect. In my implementation, I did not address the use case from [vk14] of aggregation of data from a crowd to produce net benefit. This is also something that shared use of open standards, in particular for data representation, subscription and notification, could facilitate.
Anticipation of future needs is raised as a challenge by [vk14]. With regard to my changing motivations and day-to-day requirements, I did not set out with a specific list of things I wanted to record and design the system around that. Instead, I used a flexible schemaless architecture which meant that for any new type of data I decided to log I had a minimum of new engineering to do: build a client (or potentially hook up a sensor) to generate the data; and (optionally) create a template to view it.
Working with open standards for creating, updating and deleting data helped here too, as I had the option to look for pre-existing standards compliant clients to post to my data store. Conversely, others whose data stores use the server portion of the publishing protocols can use my clients with their own storage.
Discussion of Personal Data Store architectures tends to revolve around reducing fragmentation and prioritises gathering together all kinds of data in one place [tan07]. This results in generalised tools and interfaces, which try to make it possible to do a variety of things in one place. I argue that more effective and appealing applications are specialised: particularly good at doing one thing. Whilst the data store itself is generic, standards for decentralisation permit the decoupling of clients - both for creating and displaying data - which is perhaps the best of both worlds.
Data context and integrity
Web Observatories which collect data from centralised social networking sites may be vulnerable to ingesting misinformation, ranging from subconscious selective disclosure to deliberate acts of protest against privacy infringement (as seen in The Many Dimensions of Lying Online in Chapter 3). It is difficult to say whether proliferation of personal WOs would mitigate this, but it becomes increasingly important to find ways to capture contextual information when data is recorded.
If Web Observatories begin to collect data from both decentralised and centralised services, it is natural to want to align the data so it can be combined into the same data set. However the source of the data cannot simply be discarded. The same type of data from different types of sources is not necessarily equivalent or directly comparable. Just as different centralised social media sites (and the communities and subcommunities within) have their own cultural norms and expectations, as well as technical constraints or affordances, individual personal data stores come with their own unique contextual information as well. In the decentralised case, the context for data logs may be more difficult to discern, as well as capture.
To take a concrete example: for researchers to find more meaning in the logs in my PWO they need to look at in the context of all of the systems I interact with. My system forwards text notes and longer articles to Twitter, which in term drives traffic back to my site where all my other kinds of logs can be seen. Researchers studying my data would need to consider how my awareness of my Twitter audience (directly through known followers and extended through their audiences in the case of retweets, plus how it may be used by Twitter itself, ie. the cascade) impacts all of the content I post. This might be different for someone who shares their PWO content with a different social network, or not at all. We see evidence of the impact of the network on the posting decisions of an individual in Social Media Makers in Chapter 3.
The interface used to log the data can also have an impact. Whilst I use a Web form based user interface to check in to a place, someone else might generate exactly the same data automatically by the GPS on their phone, making less of a conscious effort to record their movements. Researchers studying how people use, for example, Swarm, have the advantage of knowing that the interface used by everyone is consistent as well as being able to directly explore it themselves. I anticipate that PWOs will be far more diverse, personalised to fit into their users' day-to-day lives, and possibly inaccessible to researchers.
Limitations
Using data from QS activities for scientific research comes under fire for a number of reasons: self-reported data may be unreliable or biased; context is often lost when quantifying qualitative data; and data collection is limited to individuals who are inclined to record details about their lives [sleep]. Though I am not using the contents of my data logs in this report, the same issues apply to my recall of the effects of logging.
Perhaps most importantly, though the length of the study is significant, my sample size is 1. As such, I make no claims about generalisability or conclusivity of the results. I am documenting these experiences as a starting point, to begin to explore Personal Web Observatories in depth, and to highlight areas for focus in the future; this is similar to [tan07], in which the authors conducted their research on MyLifeBits with large amount of a single person's data as well.
I invested a considerable amount of time in building new features, fixing bugs, and making small improvements and adjustments to my PWO. As the only user and only developer, I was first to notice if something wasn't working properly, and unhindered by conflicting interests or opinions when it came to making changes. This has advantages for rapid prototyping of a somewhat novel system, as well as commitment to the ideology of dogfooding: if I don't want to use a system I've built, why should anybody else? It similarly meant that features I lost interest in fell by the wayside, whilst features I used regularly were well-maintained, so I didn't invest time in developing unnecessary functionality as I might have done had I been designing this for others. Whilst use cases and UI improvements were constrained strictly to my personal needs, and discussion of features was limited to a handful of like-minded developers, this approach was nonetheless appropriate for the purposes of this analysis.
Personal datastores for Control, Customisability and Context
This section documents over a year of developing and using a PWO. By taking the role of subject, not only developer, I have come to a better understanding of the day-to-day impact of PWO technology on an individual. 'Small data' is of interest to the academic community in terms of understanding how individuals engage with their own self-tracking activities and outputs, as well as to highlight the diversity of contexts in which data is logged and how this can impact analysis of an aggregation.
I believe that Personal Web Observatories are more useful when intimately personalised for the individual user. Small scale, pluggable components may help to enable this, and using open standards to integrate components can help with designing specialised logging clients or data interpretation interfaces. This gives users more choice to pick and choose the tools they use with their personal data store, as well as making it easier to add and remove components as desired.
Less explored here, but still pertinent, is enabling individuals to manage the relationship between different slices of their personal data or logs, and having control over who sees what. Most people do not want their logs entirely public, and may want to present different combinations of information to different audiences at different times.
Next steps
This does not mark the end of my self-tracking experiment, but the beginning of the next phase. Over the next twelve months, I expect to add to my repository: data about mood and health (specifically headaches); the people I spend time with offline, and amount of time spent chatting online; and to add more detail about exercise, and to re-start tracking sleep. I will continue to self-track publicly, but experiment with different views over my data for others, so that vistors to my site from different contexts (eg. professional) are not overwhelmed with data, nor left with an impression of inappropriate oversharing. For more detail about one approach to achieve this, read on...
Finally, I want to reiterate that providers of PWOs have a great responsibility to the individuals whose data they host. For people who engage in frequent self-tracking, a disruption in service can provoke a minor existential crisis. This is pertinent to bear in mind for researchers who wish to provide systems in order to study their users, as well as product developers building new services for personal data storage.
Audience and self-presentation
Introduction
Conflict or power imbalance arises when one party imposes frontstage expectations on another party's backstage behaviour. For example:
My landlady recently complained to me about an experience she had with a short-term guest in my shared apartment. On the day of the guest's checkout, my landlady had arranged to come over and collect the keys and return the deposit at a certain time. She arrived one hour early, without letting the guest know. She was shocked to find dishes unwashed, jars left open, food on the counter, and the guest watching a movie on the sofa in her underwear. She told me this was "not a good guest", bemoaning the untidiness.
Little does she know that that is often what the apartment looks like when I am home alone and she is not due for a visit. Nonetheless, because I have learned her tendency to turn up unannounced, as well as her penchant for tidiness, I make more effort to keep on top of cleaning day-to-day.
The problem here is that the guest was engaging in backstage activities, because she did not anticipate being observed for another hour. The guest fully intended to have the apartment clean and ready at the agreed time, and was entitled to behave as she pleased (enjoying her vacation) until then. Similarly, my landlady has some right to enter the apartment she owns when she chooses, however she does not have a right to expect that everyone therein behave constantly as if she were already present. She fails to acknowledge that her guests are going to behave differently when she is not around, and is holding her guests at fault for her flawed expectations.
One part of engaging in appropriate self-presentation is understanding and accounting for the expectations of those present: our audience. Even when thrown in to unexpected scenarios, we usually have some chance to react and accommodate in face-to-face interactions. When we are unable to do so, unpleasant social situations arise.
Online, we present a face but cannot see our audience. We may have no reliable information about who are audience are or their expectations, or we may imagine a different audience to the one(s) we really have. Furthermore, multiple audiences may access our single 'face', and we have no opportunity to adapt and change our presentation to suit their expectations.
In this section I describe a possible user interface which attempts to address the problem of accommodating audience expectations with our unified online face. It's called face: facilitate audience control of expectations. I explain it in terms of a layer that can be added on top of a basic personal data store, and for the purposes of the following mock-up, I assume that datastore to be sloph (the system from the previous section).
System design
The face system is essentially a series of stylesheets which can be applied to adapt the presentation of any data object or stream of content viewed using sloph, and a set of controls to adjust the types of content which show up at all. I came up with five dimensions which can be used to describe different aspects of myself, and along which every data object in the datastore can be rated. I can input these ratings using a custom post creation/editing application which implements the same protocol (ActivityPub) which I use for creating any kind of content in the system, so it can talk directly to my existing serverside publishing endpoint. The stylesheet(s) for a particular data object is determined by its combination of ratings. In addition, a set of controls are presented to a visitor to the site which allow them to rate how interested they are in each of the five dimensions. Adjusting this rating changes which data objects are visible, as well as the overall appearance of the homepage.
The default view is a fairly neutral representation of my online presence, which can be adjusted to give a more or less personal or professional view, and gear it towards particular topics of interest. This way, the visitor still may be confronted with content they feel is inappropriate or uninteresting, however they take responsibility for adjusting the controls to give these results. These controls introduce a collaborative approach to impression management; since I cannot react to an audience I don't know is there, maybe I can prompt my audience to give enough clues to the system that my online presence can react on my behalf.
Vocabulary and data integration
The terms I use for the ratings are published as a Linked Data ontology, available in RDF from https://terms.rhiaro.co.uk/view# (prefix: view). This is effectively an extension to the core ActivityStreams 2.0 vocabulary which I use for most of my data. These terms, somewhat flowery, are named to represent aspects of myself which I think are useful for people to distinguish my different 'faces' by. I expect these are fairly unique to me, and for this system to be applicable to other people, they would need to choose their own dimensions. Fortunately the decentralised publishing expectations of Linked Data make it possible for people to reuse existing terms and augment them with their own as they see fit.
banality: describes the more mundane things I record, like what I had for breakfast or how long I was in a cafe for.intimacy: describes posts of a personal nature, feelings, problems, hopes and dreams.tastiness: for food-related data objects, like meal logs and recipes.informative: for more formal academic output, technical comments or tutorials.wanderlust: for travel-related data objects.
To give you an idea of how different combinations of ratings along each of these axes line up: A post containing the lyrics to a song which is in my head would rate highly for banality and intimacy and low along other axes, unless the song happens to be food, travel or work-related. A restaurant review in an unfamiliar city would rate highly for tastiness and wanderlust. A complaint about bedbugs in a hostel has intimacy and wanderlust. Expressing my frustration at progress with my thesis is intimacy and informative, and a summary of a talk I did in a new city might be informative and wanderlust. My food logs are banality, tastiness and somewhat intimacy.
Each of these terms is a predicate, the value of which is an integer between 0 and 5, where 0 means 'contains no content of this nature' and 5 means 'is strictly only interesting to people who want content of this nature'.
I also use the following terms from the W3C Annotations Vocabulary [oav] (prefix: oa):
CssStyle: a class for stylesheets.styleClass: indicates which CSS classes should be applied to this resource when it is rendered.styledBy: indicates a stylesheet that should be used when rendering this resource.
A series of stylesheets are specialised to different combinations of ratings. These stylesheets exist in my triplestore as oa:CssStyle typed objects, and each is also associated with a rating along each of the face dimensions, to indicate the types of content it is most appropriate for, ie.:
</css/style.css> view:banality "5" .Some examples in the form style-name [banality, intimacy, tastiness, informative, wanderlust]:
food [5,3,5,0,0] // Meal logslyric [5,5,0,0,0] // Posts which are just song lyricswg [0,0,0,0,4] // W3C Working Group relatedphd [0,1,0,0,5] // PhD related poststrek [4,4,0,0,0] // Posts about Star Trekcheckin [5,3,0,4,0] // Posts which announce my locationfeels [0,5,0,0,1] // Posts about emotions or feelingsbanal [3,0,0,0,0] // Boring postsintimiate [0,3,0,0,0] // Intimiate poststasty [0,0,5,0,0] // Posts about foodwander [0,0,0,0,3] // Posts about traveltravel [3,5,0,0,5] // Travel plans and specific schedules
When a resource is rendered, the values for the face dimensions of the resource are compared with the values of the face dimensions for each stylesheet available, and the stylesheet which most appropriately matches the set of ratings is attached.
This way, if someone comes across an individual post out of context (eg. through seeing the results from a search engine) it is displayed in a default way which suits it the most. For example, a recipe might look like a post from a normal food blog.
User interface
The minimum viable interface to present to visitors to my homepage is a series of sliders, one for each dimension, set at neutral defaults. Visitors can move the sliders to increase or reduce the appearance of different types of posts. Turning a slider up to "5" means "show me all the posts which have a value of at most 5 for this dimension." For example:
- My Mum: as perhaps the only person in the world with a genuine interest in what I had for breakfast, will probably crank everything up to 5.
- My PhD supervisor, wanting to see my latest informal thoughts about my topic: might look only for
informativeposts, and increaseintimacyto see more heartfelt posts such as rants or complaints about technology. - My PhD supervisor, wanting to know why I'm not replying to emails or making code commits: can incrase
banality,tastinessandwanderlustto see if I have been spending my time eating, exploring and blogging about it instead of working. - A potential employer: may be interested in
informativeposts, but also where I am in the world throughwanderlust. - Someone interested in vegan food: a combination of 5 for both
banalityandtastinesswill reveal both what I eat every day, and recipes and restaurant reviews. - New friends I make whilst traveling: can maximise
wanderlustand increaseintimacyfor a personal take on my current adventure.
I can configure preset options for common types of views people might want. To take it one step further, particularly useful preset views can have their own domain names, which are simply a particular view on a particular feed of posts, and I can give the most suitable of these URLs out to people I meet offline who want to track my activities online. (Specific examples already on the cards are a food blog, whatdoveganseveneat.com, and a travel blog, homeiswherethehammockis.com).
I can also tailor the defaults based on for example, the referrer (did they click the link from Twitter) or the physical location in the world from where the traffic is coming. Similarly, if certain people I know are able to authenticate with sloph, actively making themselves known, I can default to the settings I'd prefer them to use.
Changing the default baseline depending on my current mood can give visitor to my site an immediate impression of how I'm feeling - perhaps more focussed or emotional (or hungry) - just as my facial expression and body language might give off this impression were someone to encounter me in person.
Limitations
Obviously this does not provide a solution for strict access control, privacy protection, or any kind of concealment or separation of online personas. To hide content altogether I would still need some kind of authorisation flow, or to refrain from posting it entirely. My various personas are fluid and flexible, however they are clearly linked together.
Discussion
I will briefly discuss this system in terms of the 5 Cs framework outlined in chapter 3.
Connectivity and cascade
The audience of my online presence is determined by both my connections and the cascade. In the case of sloph, I haven't implemented a subscription protocol so I do not push content out to people, and nor do I have an notion of friends or followers built in. I do cross-post content to other networks however, such as Twitter. Once content leaves my system, the audience I imagine I have is even less convincing; the likelihood of someone I do not know stumbling across my content and making their way back to my site increases. This is why it is particularly important to attempt to negotiate my impression management with visitors, lest someone on the trail of a technical blog post come across my latest opinions about Star Trek Voyager or vegan cheesecake, and leave in confusion.
Control and customisability
This system does not provide a way for me to limit the connections between the different online personas it allows me to present, which is an element of control. However, I am able to greatly alter the appearance of different kinds of information, once the designs are developed, simply by adding ratings to each resource I create. This is important for the customisability of my online presence overall. If someone is looking for a food blog, and they express that through the input options I provide, then what they'll get is a food blog that both contains the right kind of content and is visualised appropriately.
Context
Meaning is given to my data according to the context in which it is both produced and observed. The closest the observer has to understanding any of the context in which the data was produced is to look at other data logged immediately before or after the post of interest. Of course, these may be filtered out by their preferences, and I do not capture everything necessary to provide an accurate personal context (yet). At present most of my posts display the application with which they were created (though the observer is not necessarily familiar with it), but they are missing which other networks I may have cross-posted to.
Given that my data is available in a standard, machine-readable format, it may also be consumed by other applications and re-displayed, potentially removing it from the context provided by my own system. As the face dimensions are a vocabulary of my own design, I cannot assume that other systems will understand and make use of them in any way.
What my audience member provides me of their context is through their interaction with the slider controls. This is neither precise nor accurate, but perhaps nonetheless better than nothing.
Conclusions
In this chapter I have described in detail key elements of standards development within the W3C Social Web Working Group, and then discussed my personal experiences of developing systems based on these standards.
The standardisation process and its participants are part of the background context for any system which are based on these standards in the future, as the protocols many influence user interfaces and interaction models, which in turn impacts end users. The protocols themselves provide key building blocks for customisability and connectivity, as they describe ways for different types of content to be created, and for individuals to connect to one another and propagate content around a decentralised network. The implementation work highlights context which is closer to the point of data production, including the different kinds of applications which can generate the data, and the individual's mindset whilst doing so.
The experimental content display system, face, ties together connectivity and customisability by creating an environment in which the subject and their audience can collaborate in forming an appropriate self-expression, despite neither being co-present.
This chapter outlines a journey from theoretical ideas about how to build systems, to working software, by way of a consensus-based formal standardisation process with many players and stakeholders, as well as personal experimentation and reflection. Many Social Web systems have their own stories which can be traced along these lines, though rarely are they told in completeness. This chapter contains only my perspective, and only one software implementation, when there are many others which likely differ.
In the next and final chapter, I will bring together my contributions throughout this thesis, and reflect on the research questions I asked at the beginning.
Standards and self-presentation
We have in previous chapters established that online self-presentation is greatly more complex than listing attributes and a photo on a Web page. For decentralised systems to emulate the multitude of self-presentation possibilities provided by mainstream centralised systems today they must coordinate across a range of potential user activities and interactions. Common protocols enable disparate systems to communicate without any prior arrangements. Specifications describing such protocols must be agreed upon and published in such a way that makes them easy to find, and appear authoritative enough that developers of decentralised systems are persuaded to implement them.
This section documents and furthers the standardisation process, as part of the work of the W3C Social Web Working Group. Chapter 4 includes a survey of the specifications and their implementations at the time of writing; here I provide a behind-the-scenes look at and contribution to their development.
Standardisation as Context
The standards developed by the Social Web Working Group will be used as the basis for systems which incorporate social features, and as such, create the opportunity for users of the system to present some aspects of their personhood in an online space. This chapter goes into detail about the non-technical parts of development of these standards.
The reason for this is as follows: the formation of the Working Group and its charter design; the individual members of the Group and their particular interests and experiences; and the processes of the W3C, all serve to make up part of the context (one of the 5 Cs from Chapter 3) of any systems built from these standards. This is an example of things to analyse, or at least take note of, with respect to the industrial or organisational context in which users of social systems are engaging in self-presentation.
The standardisation process
Once a group is formed and participants are in place, the W3C has many processes in place to facilitate standards development. These processes have ramifications on the end result of worked produced by Working Groups, so I will outline key processes here.
Specifications advance usually over the course of one to two years, through a number of stages of increasing stability, to bring them to a final status of REC (recommendation). Each stage (see also [w3c-maturity]) is designed to elicit development, input, and review from different qualified parties to iron out bugs, correct omissions, and generally make sure the specification will do what it is intended to do. While direct input is limited to Working Group members, specification development is carried out in public. Each date-stamped draft is online for anyone to review, mailing list archives, meeting minutes, wiki pages, and (at least in the case of the Social Web Working Group) IRC logs are publicly visible. Working Groups tend to take public comments over a specific mailing list, or as GitHub issues, and are obliged to be responsive and reach a considered resolution on how to handle all feedback so that commenters feel heard.
Specifications are maintained as Editor's Drafts (ED) throughout their life cycle. An ED is the most up to date version of the specification, and updated at the editor's discretion. Working Groups do not have the authority to publish specifications unsupervised. Each Working Group is supported by one or two W3C employees (Team Contacts), and at each transition from one specification maturity level to the next, a request is sent to the W3C Director, who reviews the relevant information, checks that the Working Group have been handling feedback from commenters appropriately, clarifies any points of confusion, and grants or denies the request.
The first formal iteration (hosted at the W3C domain) is the First Public Working Draft (FPWD). An ED need not be perfect, or even complete, but when it is sufficiently outlined the Working Group participants vote to publish the FPWD. This is the first stage of the Working Group committing to progress the document towards recommendation. As the specification is discussed and implemented, and feedback comes in, features are added, removed and refined. After each batch of major changes to the ED, the Working Group may vote to publish updated Working Drafts (WD). WDs are essentially official snapshots at particular points in time. As a specification becomes stable (ie. it receives fewer and fewer major changes) the Working Group reaches out further to solicit 'wide review' from relevant communities. These may be outside the W3C as necessary, but there are specific groups inside the W3C who are expected to review all specifications along particular dimensions; namely: security and privacy, internationalisation, and accessibility.
When the specification is sufficiently stable, and wide review has been achieved, the Working Group may vote to advance to Candidate Recommendation (CR). The CR phase lasts for a minimum of four weeks. This commences a broader call for implementations from outside of the W3C, begins the window in which W3C members must disclose patent conflicts, and prompts W3C Advisory Committee members to review the specification. If major (non-editorial) changes are made to the specification during this phase (which is not uncommon as a result of third-party implementation feedback), then a new CR must be published, which restarts the four week time period. During this time, the editors and their collaborators should be polishing up official test suites, and soliciting implementation reports. The specification can advance to Proposed Recommendation (PR) when it meets a CR exit criteria previously defined by Working Group consensus. In the case of the Social Web Working Group, specifications are expected to have tests and reports for at least two independent implementations of each feature of a specification (where 'feature' is defined per specification). During PR, which must also last a minimum of four weeks, Advisory Committee representatives are re-prompted to review the spec. This is the last time during which anyone can make a Formal Objection to the specification's progression, or raise patent conflicts. Finally, if enough positive Advisory Committee reviews are received, the W3C Director approves the specification to transition to REC. It is carved in stone.
Why am I telling you all this?
This is an example of organisational processes having impact on technology design long before the technology is in the hands of end users. The specifications of the Social Web Working Group were not only moulded by their editors and Working Group participants, but reshaped and influenced by W3C staff and by representatives of paying W3C Members who weren't participating in the Group directly. Specifications were poked and tweaked by other Working Groups who do not specialise in the Social Web (most contentious input came from the Internationalisation (i18n) Working Group), as well as critiqued by complete outsiders at every step of the way.
Most specification editors in the Social Web Working Group were invited experts, and thus not paid by an organisation for their contributions. They were working on these specifications, attending weekly telecons, and often quarterly face-to-face meetings, on their own time, and own dime. Editors are also burdened with test suite development; no small task. The W3C process imposes structure, deadlines and deliverables to the specification development process that may be missing (or certainly different) were the specs advanced elsewhere. These deadlines and review processes ultimately affect what is included in a specification, and what is removed. Smaller specs are easier to review, easier to test, and therefore faster to progress. This tended to mean that when in doubt, features were dropped or marked as 'at risk' rather than have them hold up progress. In particular, ActivityStreams 2.0 was brutally trimmed down over the years, and requests for additions to the vocabulary were automatically rejected after a certain point for fear of slowing things down. I wonder how these exclusions will impact future software designed around AS2.
Something else worth bearing in mind is that for all of this process, it is commonly held that most 'regular Web developers' don't know about or don't care about (or both) the difference between the different maturity levels of W3C specifications, or even the difference between a Recommendation and a Note. This makes it fairly easy for developers to be implementing software on the basis of an out of date document, or giving weight to a protocol design that was ultimately rejected or even unfinished. Not everything with the W3C stamp on has been fully thought through or passed quality tests, but not every developer realises this.
The Social Web Working Group charter
Technical specifications, at least those produced by the W3C, are intended for software developers. A mark of the success of a standard is when multiple developers, who have no knowledge of each others' activities, can independently implement the specification into code and have their systems interoperate successfully.
Contributions to W3C standards may be made by individuals representing themselves (if invited and approved by Working Group chairs), but more so by representatives of organisations which pay for membership to the W3C. As the Web is an open platform on which anyone can build, there is a lot of space for many ways to solve the same problems. This is a virtue in that it promotes innovation and competition amongst Web services, but a problem if it results in technical fragmentation of solutions, whereby end users are forced to choose one and forgo (or uncomfortably juggle) interaction with others (remember the 'browser wars' of the 1990s and early 2000s? [bwars]). Organisations join the W3C so that their interests may be represented as they collaborate to produce standard ways of interacting with Web technologies in order to reduce the negative impact of technical fragmentation on end users.
As has been raised on multiple occasions by this thesis, the Social Web is presently in a state of technical fragmentation [dcent]. End users, also known as people or human beings, are living with the effects of this on a daily basis. Beyond being a mere inconvenience (not being able to port one's friends from Twitter to Facebook), the competition between social platforms has developed in such a way that people are locked in to services. Once one depends upon a particular social networking platform for communication and content creation it is almost impossible to change provider. Platforms like this have come to be known amongst decentralisation advocates as silos, in that they do not let information flow in or out [timblfuture].
These closed systems bring a plethora of social, cultural, political and economic issues, which have been touched upon at various stages elsewhere in this thesis and we will not detail further here. The Social Activityact, which includes the Social Web Working Group, was created in W3C with an eye to promoting interoperability between social systems, and breaking down some of the walls of silos.
Objectives of the Social Web Working Group were to produce standards for:
Working Group participants and audience
Working Groups may be chartered with the agreement of 5% of the W3C membership [wg-charter]and the Social Working Group was convened in July 2014wg-me. One of the W3C Members which helped found the Working Group was the Open Social Foundation, which was a collaboration between several large companies and expected to use their influence to drive participation in the Working Group. The Open Social Foundation dissolved upon the beginning of the Social Web Working Group, handing its assets to W3C [wg-os].
It is noteworthy that no major social networking companies are members of the W3C Social Web Working Group. Big companies who joined were those motivated primarily by producing social standards for use in business. Many organisations use proprietary, and often in-house, social networking platforms for their employees to communicate, organise, and share information. The benefit of standards in this scenario is to enable inter-organisational social interaction, to better smooth partnership and other business processes. This outlook set the tone for much of the early discussions in the group.
However, over the past two and a half years, active participation in the group has dwindled to such an extent that the group consists of mostly invited expertswg-ie. As time progressed, representatives of organisations interested in social business were reassigned and their participation in the group diminished. This dramatically (although it wasn't noticeable at the time) altered the tone of the group.
Several invited experts currently in the Group are representing their own interests, passionate about social standards they can implement for themselves. Others are from open source or free software communities, and want existing or emerging projects to interoperate with regard to social interactions, as a way to add value for users but also to uphold principles of their users' freedom to choose to take their data elsewhere. These two groups are by no means mutually exclusive.
How can Social Web standards possibly be adopted widely enough to have any impact without the support of major social networking platforms? An informal hypothesis by various members of the Working Group is that there are many more (e-)industries who can benefit from social networking than the ones who make advertising- and data-mining-supported social platforms. Such businesses either produce tailored in-house solutions to the very specific corner of social media they need (think Amazon reviews) or embed functionality provided by a major platform (think adding a Facebook Like button). Some have moved all of their publishing and customer interaction to one or more mainstream social networking platforms (some newspapers and magazines; restaurants and cafes). Yet other services have been designed from the ground up to depend on a major platform for the provision of their service at all (marketing and customer analytics software; many games).
Complete dependence is risky, as has been shown on countless occasions when, for example, Twitter changes its developer Terms of Service so that existing third-party applications are suddenly in violation [tw-api, tw-api2, tw-api3, tw-api4]; or Facebook changes its API, resulting in an endless cycle of unpredictable code maintenance [fb-api, fb-api2].
Depending on centralised platforms for a customer base results in either excluding non-users of the chosen platform, or having to manage a presence on multiple platforms. The circle continues with the availability of services designed to help manage broad social media presence over multiple platforms; these are in the category of social-platform-dependent business models.
Organisations which do not want to depend on existing services tend to have to build their own, creating a burden of storing data (securely and privately) on behalf of their customers when this may not even be central to their business process. Standards which allow their customers to point to a personal data store that they already have would be an advantage in this case.
It is thus organisations for which 'social' is an enhancement (albeit in many cases a critical one) rather than the core of their revenue stream that may be persuaded to invest time in implementing open Web standards. A result of this adoption can contribute towards normalising expectations of more decentralised social interactions from the perspective of end users, too. One could argue that situation with the Social Web is at a maturity level analogous to that of the software industry in the decade before the free software movement was re-launched in the early 1980s.
Unfortunately there has been low participation from this category of organisation as well, so the Working Group has not necessarily managed to appreciate their needs.
In summary, the Social Web WG specifications are targeted at:
Further, with increasing public awareness of the privacy and freedom implications of handing all data to a select few organisations, these organisations may seek new business models (beyond selling consumer data) and innovate on other fronts in order to retain user trust.
API Requirements
An early activity of the Working Group was to write 99 "user stories" describing actions that people should be able to carry out using systems based on standards produced by the group. The goal of this was to focus efforts on the most important standards to be worked on, to meet the needs that appeared most critical to members of the group. Most group members contributed one or more user stories, and they varied based on the perspective of the individual or organisation they represented. The group then voted (-1, -0, 0, +0 or +1) on every user story, and selected a top eight to prioritise.
My subsequent contribution was to derive API requirements from the shortlisted user stories.
Process
Results
The simplified story requirements and their respective labels are listed in table 12. The labelled requirements, with descriptions derived from the requirements of the combined user stories, are as follows:
Competing specifications
As this section is concerned with providing insight into the process that resulted in the outcomes of the Social Web Working Group, I will now provide background for a key technical direction that was taken. The work of the Group commenced with some guidelines about deliverables in the charter, but not a specific list; this was something the participants had to figure out in order to meet the previously described API Requirements.
The technologies promoted by active participants of the Working Group settled into roughly three categories: microformats-based, JSON-based, and RDF-based, with some small points of overlap. The proponents of JSON-based technologies tended to come from the Open Social Foundation background, with experience in open source social systems designed to support multiple users per server/instance. The microformats supporters brought the perspective of individuals running their own personal implementations of social systems, federating with other individuals on a small scale. The RDF advocates brought experience with large-scale data modelling, open data publishing and data integration, often in an academic or proprietary business context. Producing JSON-based protocols was a requirement of the Working Group charter; the other technologies had the potential to still meet this requirement through the microformats2 parsing algorithm in the former case, and JSON-LD in the latter case. These three perspectives are valuable and in theory complementary, but in practice caused drawn out arguments, ideological disagreements, and frequent misunderstandings.
The participants set about bringing their preferred solutions up to standard, and submitted them to the Working Group as Editor's Drafts. I started work on documenting the commonalities between the specifications with the intent that we'd manage to converge them into a single optimal protocol (this is the origin of Social Web Protocols). After many months of work, many hours of telecons, and several face-to-face meetings, technical disagreements and general unwillingness to compromise (all captured for posterity in meeting minutes, mailing list discussions, and GitHub issues) resulted in the convergence effort stalling.
Even leaning on participants' past experiences (see Chapter 4) of prior systems, this was still relatively untrodden ground, so it was never clear (to me, and other more neutral parties) which technology or ideology was most likely to succeed. In most disagreements, it was never obvious that one party was right and the other was wrong. Eventually the Working Group as a whole acknowledged this, and resolved to move forward all of the prospective standards separately, and to stop trying to force convergence.
This decision was controversial in the eyes of other members of the wider W3C community who were not members of Social Web Working Group, and potentially confusing for developers looking for the solution to decentralised Social Web protocols. However the effect was that specification editors stopped arguing about why their way was better, and were free to move their work forward without needing to defend their decisions from people who fundamentally disagreed with their underlying assumptions. Specification editors who had accepted their differences began to help each other, and to share findings and experiences (because they are all working towards the same end goal, after all).
Ultimately the Working Group has a produced a suite of specifications that is not as coherent as it might have been had the participants been united around fundamental technical decisions. However, we also have a better understanding of how to bridge these different perspectives (in terms of writing code, as well as in terms of discussions) than we would have if one perspective had dominated the group and the others had continued their own work elsewhere. Whilst the "glue code" approach is advocated by [crit12], it's too early to tell if this means we increase the chance of these standards being adopted (because we have something to please a broader spectrum of developers out there) or decrease the chances (because we look indecisive and nobody will take the outputs seriously). Similarly, if we see wide uptake of these standards, will we get three (or more) fragmented decentralised Social Webs because developers are opinionated, and writing bridging code is too complicated; or will the efforts towards bridging the approaches be taken up so that completely different protocol stacks can interoperate on some level at least?
The trials and tribulations of the Social Web Working Group have the potential to have far-reaching consequences for the future of the decentralised Social Web, and as such, on how people are able to present and express themselves online. Even if the Working Group's final outputs are not an ultimate solution, the authority given by the W3C standardisation process means that they will at least be referred to, and probably built upon, as the decentralised Social Web grows.
Social Web Protocols
Having covered the context of the specifications' development, we now dive into their actual functionality. This section introduces the Social Web Protocols, a description of the specifications produced by the Social Web Working Group, and is arranged by the previously derived API requirements (read, publish, notify, subscribe). Some content in this section is published as a W3C Working Group Note [swp]. Systems can be built with these protocols in great variety. Incorporating the standards produced by the Social Web Working Group into a system does not automatically mean the system is empowering to its users; the protocols provide only a skeleton, leaving much open for specialisation by developers. Conformance to these protocols does however imply that users are able to move their data between systems; that clients and servers are somewhat decoupled so users have more flexibility with regards to tools; and that users are not compelled to follow their network or locked into the system where their friends are.
Overview
People and the content they create are the core components of the Social Web; they make up the social graph. The Social Web Protocols describe standard ways in which people can:
regardless of what that content is or where it is stored.
These components are core building blocks for interoperable social systems.
Each of these components can be implemented independently as needed, or all together in one system, as well as extended to meet domain-specific requirements. Users can store their social data across any number of compliant servers, and use compliant clients hosted elsewhere to interact with their own content and the content of others. Put simply, Social Web Protocols tells you, according the recommendations of the Social Web Working Group:
The following table shows the high level requirements according to the Social Web Working Group charter and the Social API Requirements, and how the specifications of the Working Group overlap with respect to each.
The specifications may be implemented alongside each other in various configurations. Figure 17 shows a high level view of how different parties in a social system may be connected together. The arrows show data flowing through the system, and the labels of the arrows are the protocols by which data is enabled to flow.
Some of the specifications overlap in functionality, or complement each other explicitly. This list provides detail on some key relations between different specifications, and table 14 provides a summary.
To read (approx): if I have x, it uses y to _.
n/a means there is no explicit relation between the specs, but does not mean to suggest they can't be used together.
bridge means these specs have overlapping functionality and bridging code is needed for interoperability.
Reading
An individual's self presentation online can be partially composed of content they produce and interact with. The read label covers how these are exposed for consumption by others. This may include permissions or access control, which could require the reader to identify themselves before content is made available. Different types of content and interactions should be discoverable, perhaps according to criteria like the type of content, a group or individual with which it is associated, or through its association with other content (eg. through replies).
Content representation
ActivityStreams 2.0 (AS2) models content and interactions as objects and activities. AS2 includes a vocabulary for modelling different types of objects and activities as well as various relations they might have with other objects (including user profiles) and activities. The AS2 syntax describes a consistent structure for objects and activities including sets of objects and activities as collections. Collections can be explicitly created and updated by a user (like adding photos to an album) or generated automatically as a result of other user actions or the properties of certain objects/activities (eg. a list of followers of a user). AS2 does not specify how objects, activities, or collections come into existence, only what they look like once they do.
AS2 content must be served with the Content-Type
application/activity+jsonor, if necessary for JSON-LD extended implementations,application/ld+json; profile="https://www.w3.org/ns/activitystreams". Content must be described using the AS2 vocabulary, and may use other vocabularies in addition or instead, per the extension mechanism.To make content available as ActivityStreams 2.0 JSON, one could do so directly when requested with an appropriate
Acceptheader (eg.application/activity+jsonorapplication/ld+json), or indirectly via arel="alternate" type="application/activity+json"link . This link could be to a different domain, for third-party services which dynamically generate ActivityStreams 2.0 JSON on behalf of a publisher.AS2 builds upon ActivityStreams 1.0 [as1] and is not fully backwards compatible; the relationship between AS1 and AS2 is documented in the AS2 spec.
Because AS2 is a data model, it does not recommend how data should be displayed. Its utility is in enabling a consistent representation of social objects and activities to be passed between potentially disconnected systems (eg. from Alice's social network to Bob's). The systems consuming the data are responsible for rendering it appropriately. This means that system designers can provide their users with options for customising the presentation data that may constitute their profiles.
Extending AS2
AS2 specifies a finite set of object and activity types and properties. These are a baseline set of common social interactions which can be extended upon by systems which need additional terms or more specific variations. The extension mechanism is based on Linked Data, via JSON-LD. Developers are expected to publish documentation and an RDF representation of their terms at a domain under their control, and refer to terms by URI in the normal manner. Further, the Social Web Working Group describes a mechanism by which well-used extensions are included with the AS2 namespace document by means of a W3C Community Group vetting process. The advantage of this is that implementations can adopt common extensions easily, without needing to include additional namespaces. It also makes extensions more discoverable for newcomers to AS2.
The first such extension is in fact ActivityPub. ActivityPub uses ActivityStreams 2.0 for all data in all requests, and also adds additional terms to the AS2 namespace. Thus, ActivityPub requires requests have the Content-Type
application/ld+json; profile="https://www.w3.org/ns/activitystreams".Other ways of representing content
Despite AS2 being the recommended syntax and vocabulary of the Working Group, some specifications use different or broader mechanisms. This helps to let developers pick and choose different specifications for different tasks even if they prefer not to use AS2:
AcceptandAccept-PostHTTP headers) about using different RDF syntaxes, as well.topicURL.Objects and streams
Whichever syntax and vocabulary is used, there are some general recommendations for representing objects (individual entities) and streams (sets or collections of objects).
idproperty. This URL should resolve to return the properties of an object; what is returned may depend on the requester's right to access the content, determined by authentication and/or authorisation.Special streams
Streams are represented in AS2 as a
CollectionorOrderedCollection. ActivityPub defines some special usages; two streams that must be accessible from a user's profile, and four which are optional, via the following properties:inbox: A reference to an AS2 collection comprising all the objects sent to the profile's owner.outbox: An AS2 collection comprising all the objects produced by the profile's owner.following: An optional AS2 collection of the users that this user is following.followers: An optional AS2 collection of the users that follow this user.likes: An optional AS2 collection of everyobjectfrom all of the user'sLikeactivities (generated automatically by the server).streams: An optional list of supplementary AS2 collections which may be of interest.ActivityPub permits arbitrary streams to be updated through specifying special behavior for the server when it receives activities with types
AddandRemove. When a server receives such an activity in theoutbox, and thetargetis a stream, it must add theobjectto thetarget(forAdd) or remove theobjectfrom thetarget(forRemove).Two kinds of special streams are
inboxandoutbox. When read (ie. with an HTTPGETrequest) they return ordinary streams of objects, but they also double as endpoints which can bePOSTed to directly to add objects, for delivery of notifications and publishing new content respectively.The
inboxis a notion shared by ActivityPub and Linked Data Notifications, however in order to be read by both ActivityPub and LDN clients, publishers must relate the stream to the objects it contains using both theas:itemsandldp:containspredicates. This is an unfortunate discord, but since ActivityPub is immovably tied to AS2 and LDN is immovably tied to compatibility with the vocabulary of existing Linked Data Platform servers, there was really no compromise to be had. Fortunately this bridge is relatively minor in terms of coding, once a developer is aware of it.Publishing
Publishing in this context incorporates creating new content, and updating or deleting existing content. The ability to publish content and generate (and update or remove) new data is critical to online self-presentation, in particular it is part of customisability in building an online profile.
Content generated through a client (such as a web form, mobile app, sensor, smart device) is created when it is sent to a server for processing, where it is typically stored and usually published (either publicly or to a restricted audience, in human- and/or machine-readable forms). Clients and servers may independently support creating, updating and deleting; there are no dependencies between them.
Authentication and authorization between clients and servers for creating content are not included in these specifications, as they are considered orthogonal problems which should be solved elsewhere.
The two specifications recommended by the Social Web Working Group for publishing are Activitypub and Micropub. They use similar high level mechanisms, but differ in requirements around both the vocabularies and content types of data. ActivityPub contains a client-to-server API for creating ActivityStreams 2.0 objects and activities, and specifies additional responsibilities for clients around addressing objects, and for servers around the side-effects of certain types of objects. Micropub provides a basic client-to-server API for creating blog-post type content which can be implemented alone and is intended as a quickstart for content creation, on top of which more complex (but optional) actions can be layered.
Both provide similar media endpoints for uploading files.
Neither ActivityPub nor Micropub define APIs for publishing based on HTTP verbs, and thus differ from the more RESTful Linked Data Platform (LDP).
Creating
The publishing endpoint of ActivityPub is the
outbox. Clients are assumed to have the URL of a (ideally authenticated) user profile as a starting point, and discover the value of thehttps://www.w3.org/ns/activitystreams#outboxproperty found at the profile URL (which should be available as JSON[-LD]). The client then makes an HTTPPOSTrequest with an ActivityStreams 2.0 activity or object as a JSON[-LD] payload with a content type ofapplication/ld+json; profile="https://www.w3.org/ns/activitystreams". The URL of the created resource is generated at the discretion of the server, and returned in theLocationHTTP header. This is an appropriate protocol to use when:Side-effects of creating content with ActivityPub are for the most part adding things to various different collections collections (likes, follows, etc); but also include requirements about blocking users, and a hook to enable federated servers.
The publishing endpoint for Micropub is the
micropubend point. Clients discover this from a user's URL via arel="micropub"link (in an HTTPLinkheader, or an HTML element). Clients make ax-www-form-urlencodedPOST request containing the key-value pairs for the attributes of the object being created. The URL of the created resource is generated at the discretion of the server, and returned in theLocationHTTP header. Clients and servers must support attributes from the Microformats 2 h-entry vocabulary. Micropub also defines special reserved attributes (prefixed withmp-) which can be used as commands to the server. Any additional key names sent outside of these vocabularies may be ignored by the server.Micropub requests may alternatively be sent as a JSON payload, the syntax of which is derived from the Microformats 2 parsing algorithm. This is an appropriate protocol to use when:
Updating
Content is updated when a client sends changes to attributes (additions, removals, replacements) to an existing object. If a server has implemented a delivery or subscription mechanism, when an object is updated, the update MUST be propagated to the original recipients using the same mechanism.
ActivityPub clients send an HTTP
POSTrequest to theoutboxcontaining an AS2Updateactivity. Theobjectof the activity is an existing object, and the fields to update should be nested. If a partial representation of an object is sent, omitted fields are not deleted by the server. In order to delete specific fields, the client can assign them anullvalue. However, when a federated server passes anUpdateactivity to another server'sinbox, the recipient must assume this is the complete object to be replaced; partial updates are not performed server-to-server.Micropub clients perform updates, as either form-encoded or JSON POST requests, using the
mp-action=updateparameter, as well as areplace,addordeleteproperty containing the updates to make, to the Micropub endpoint.replacereplaces all values of the specified property; if the property does not exist already, it is created.addadds new values to the specified property without changing the existing ones; if the property does not exist already, it is created.deleteremoves the specified property; you can also remove properties by value by specifying the value.Deleting
Content is deleted when a client sends a request to delete an existing object. If a server has implemented a delivery or subscription mechanism, when an object is deleted, the deletion MUST be propagated to the original recipients using the same mechanism.
ActivityPub clients delete an object by sending an HTTP POST request containing an AS2
Deleteactivity to theoutboxof the authenticated user. Servers MUST either replace theobjectof this activity with a tombstone and return a410 Gonestatus code, or return a404 Not Found, from its URL.Micropub delete requests are two key-value pairs, in form-encoded or JSON:
mp-action:deleteandurl:url-to-be-deleted, sent to the Micropub endpoint .Subscribing
An agent (client or server) may ask to be notified of changes to a content object (eg. edits, new replies) or stream of content (eg. objects added or removed from a particular stream). This is subscribing. This is part of the process of creating links between individuals in a social network, and other individuals or resources; part of connectivity. Specifications which contain subscription mechanisms are ActivityPub and WebSub.
Nothing should rely on implementation of a subscription mechanism. That is, implementations may set themselves up to receive notifications without always being required to explicitly ask for them from a sender or publisher: see delivery.
Subscribing with
as:FollowActivityPub servers maintain a Followers collection for all users. This collection may be directly addressed, or addressed automatically or by default, in the
to,ccorbccfield of any Activity, and as a result, servers deliver the Activity to theinboxof each user in the collection.Subscription requests are essentially requests to be added to this collection. They are made by the subscriber's server
POSTing aFollowActivity to the target'sinbox. This request should be authenticated, and therefore doesn't need additional verification. The target server then SHOULD add the subscriber to the target's Followers collection. Exceptions may be made if, for example, the target has blocked the subscriber.This is a suitable subscription mechanism when:
Since delivery is only a requirement for federated servers, prospective subscribers will not be able to
POSTtheirFollowactivity to theinboxof a profile which is on a non-federated server (expect a405 Method Not Allowed), and thus are not able to subscribe to these profiles. In this case, prospective subscribers may wish to periodically pull from the publisher'soutboxinstead.Delegating subscription handling
WebSub provides a mechanism to delegate subscription handling and delivery of content to subscribers to a third-party, called a hub. All publishers need to do is link to their chosen hub(s) using HTTP
Linkheaders or HTML<link>elements withrel="hub", and then notify the hub when new content is available. The mechanism for notifying the hub is left deliberately unspecified, as publishers may have their own built in hub, and therefore use an internal mechanism.Hubs and publishers which would like to agree on a standard mechanism to communicate might consider employing an existing delivery mechanism, namely Linked Data Notifications (fig. [subscription-notification]) or Webmentionsub-wm.
objectis thetopicURL and thetargetis the hub itself. The hub can use this information to fetch new content for subsequent delivery to subscribers.The subscriber discovers the hub from the publisher, and sends a form-encoded
POSTrequest containing values forhub.mode("subscribe"),hub.topic(the URL to subscribe to) andhub.callback(the URL where updates should be sent to, which should be 'unguessable' and unique per subscription). The hub and subscriber carry out a series of exchanges to verify this request.When the hub is notified of new content by the publisher, the hub fetches the content of the
topicURL, and delivers this to the subscriber'scallbackURL.This is a suitable subscription mechanism when:
LDN Receivers can receive deliveries from WebSub hubs by using the
inboxURL as thehub.callbackURL and either only subscribing to resources published as JSON-LD or accepting content-types other than JSON-LD.Delivering
A user or application may wish to push a notification to another user that the receiver has not explicitly asked for. For example to send a message or some new information; because they have linked to (replied, liked, bookmarked, reposted, etc) their content; because they have linked to (tagged, addressed) the user directly; to make the recipient aware of a change in state of some document or resource on the Web. This is also part of connectivity, as well as a potential way to make individuals aware of how their content is cascaded throughout a network, and how they are connected to others of whom they were previously unaware. The Social Web Working Group specifications contain several mechanisms for carrying out delivery; they are listed here from general to specialsed.
Targeting and discovery
The target of a notification is usually the addressee or the subject, as referenced by a URL. The target may also be someone who has previously requested notifications through a subscription request. Once you have determined your target, you need to discover where to send the notification for that particular target. Do this by fetching the target URL and looking for a link to an endpoint which will accept the type of notification you want to send (read on, for all of your exciting options).
Bear in mind that many potential targets will not be configured to receive notifications at all. To avoid overloading unsuspecting servers with discovery-related requests, your application should employ a "back-off" strategy when carrying out discovery multiple times to targets on the same domin. This could involve increasing the period of time between subsequent requests, or caching unsuccessful discovery attempts so those domains can be avoided in future. You may wish to send a
User-Agentheader with a reference to the notification mechanism you are using so that recipient servers can find out more about the purpose of your requests.Your application should also respect relevant cache control and retry headers returned by the target server.
Generic notifications
LDN provides a protocol for sending, receiving and consuming notifications which may contain any content, or be triggered by any person or process. Senders, receivers and consumers can all be on different domains, thus this meets the criteria for a federation protocol. This is a suitable notification mechanism when:
LDN functionality is divided between senders, receivers and consumers. The endpoint to which notifications are sent is the
inbox. Any resource (a user profile, blog post, document) can advertise itsinboxso that it may be discovered through an HTTPLinkheader or the document body in any RDF syntax (including JSON-LD or HTML+RDFa). To this Inbox, senders make aPOSTrequest containing the JSON-LD (or other RDF syntax perAccept-Postnegotation with the receiver) payload of the notification. The receiver returns a URL from which the notification data can be retrieved, and also adds this URL to a list which is returned upon aGETrequest to the Inbox. Consumers can retrieve this Inbox listing, and from there the individual notifications, as JSON-LD (optionally content negotiated to another RDF syntax). An obvious type of consumer is a script which displays notifications in a human-readable way.An existing LDP implementation can serve as an LDN receiver; publishers simply advertise any
ldp:Containeras theinboxfor a resource.The payload of notifications is deliberately left open so that LDN may be used in a wide variety of use cases. However, receivers with particular purposes are likely to want to constrain the types of notifications they accept. They can do this transparently (such that senders are able to attempt to conform, rather than having their requests rejected opaquely) by advertising data shapes constraints such as SHACL. Advertisement of such constraints also allows consumers to understand the types of notifications in the Inbox before attempting to retrieve them. Receivers may reject notifications on the basis of internal, undisclosed constraints, and may also access control the Inbox for example by requiring an
Authorizationheader from both senders and consumers.WebSub publishers deliver content to their hub, and hubs to their subscribers using HTTP
POSTrequests. The body of the request is left to the discretion of the sender in the first case, and in the latter case must match the Content-Type of and contain contents from thetopicURL.Activity notifications
ActivityPub uses LDN to send notifications with some specific constraints. These are:
POSTrequests are authenticated.ActivityPub specifies how to define the target(s) to which a notification is to be sent (a pre-requisite to LDN sending), via the AS2 audience targeting and object linking properties.
ActivityPub also defines side-effects that must be carried out by the server as a result of notification receipt. These include:
Create,UpdateandDeleteactivities.Undoactivity.Follow,LikeandBlockactivities.AddandRemoveactivities.ActivityPub actor profiles are linked to their inboxes via the
https://www.w3.org/ns/activitystreams#inboxproperty. This is an alias (in the AS2 JSON-LD context) for LDN'shttp://www.w3.org/ns/ldp#inbox. Applications using a full JSON-LD processor to parse these documents will see these terms as one and the same. Applications doing naive string matching on terms may wish to note that if you find anldp:inboxit will acceptPOSTrequests in the same way as anas:inbox.Mentioning
Webmention provides an API for sending and receiving notifications when a relationship is created between two documents by including the URL of one document in the content of another. It works when the two documents are on different domains, thus serving as a federation protocol. This is a suitable notification mechanism when:
There are no constraints on the syntax of the source and target documents. Discovery of the Webmention endpoint (a script which can process incoming webmentions) is through a link relation (
rel="webmention"), either in the HTTPLinkheader or HTML body of the target. This endpoint does not need to be on the same domain as the target, so webmention receiving can be delegated to a third party.Webmentions are verified by the server dereferencing the source and parsing it to check for the existence of the target URL. If the target URL isn't found, the webmention MUST be rejected.
Webmention uses
x-www-form-urlencodedfor the source and target as parameters in an HTTP POST request. Beyond verification, it is not specified what the receiver should do upon receipt of a Webmention. What the webmention endpoint should return on aGETrequest is also left unspecified.Delivery interop
This section describes how receiver implementations of either Webmention or LDN may create bridging code in order to accept notifications from senders of the other. This can also be read to understand how a sender of either Webmention or LDN should adapt their discovery and payload in order to send to a receiver of the other.
Webmention receivers wishing to also accept LDN
POSTs at their Webmention endpoint MUST:rel="http://www.w3.org/ns/ldp#inbox"in addition torel="webmention"(in theLinkheader, HTML body or JSON body of a target).POSTrequests with the Content-Typeapplication/ld+json. Expect the body of the request to be:source->@idandtarget->@idvalues as thesourceandtargetof the Webmention, and proceed with verification.201 Created, it MUST return aLocationheader with a URL from which the contents of the request posted can be retrieved.202 Acceptedis still fine.LDN receivers wishing to also accept Webmentions to their Inbox MUST:
rel="webmention"in addition torel="http://www.w3.org/ns/ldp#inbox"(in theLinkheader, HTML body or JSON body of a target).POSTrequests with a content typeapplication/x-www-form-urlencoded. Convert these requests from:201 Createdwith aLocationheader or202 Accepted.Webmention as AS2
A webmention may be represented as a persistent resource with AS2. This could come in handy if a Webmention sender mentions a user known to be running an ActivityPub federated server. In this case, the sender can use an AS2 payload and carry out delivery of the notification per ActivityPub/LDN.
A receiver or sender may want to augment this representation with the relationship between the two documents, and any other pertinent data. In the receiver's case, this could be gathered when they parse the source during the verification process. For example:
Protocols for Customisability and Connectivity
The protocols produced by the Social Web Working group deal with creating content and social interactions, and propagating them around a network. They give varying degrees of freedom to implementors about when and how to pass data between servers, and say little to nothing about the presentation of the content or user interface associated with interactions. The core types of social objects and interactions indicate an initial constraint how users will be able to behave within a system, though implementations can extend from this baseline as they see fit. How and whether they do so remains to be seenext. The protocols do not deal with changes to attributes of a user profile, however.
Engaging in particular types of public or partially public social interaction online is a way to shape one's self-presentation. Being able to choose which of these interactions are used and presented outwardly is part of customisability. Building social interactions from a common base of standard ones means that the semantics of these activities can be shared across platforms.
Interoperable implementations based on these protocols increase the potential connectivity of individuals online, as they are no longer constrained to interacting with others within the confines of a single technical system. People can potentially find and connect with, follow and subscribe to, other people and content no matter where it is published. This brings with it further complications around how peoples' activities are presented across disparate systems. Users have even less surety with regards to what their content will look like when it is seen by others if they have no way of know what kinds of systems their content is being transmitted to or through.
Remaining problems
Some of the problems which the Social Web Working Group did not address (and nor were chartered to) are listed here. This list is substantial, and many of the items seem critical for the future of the Social Web, however I posit that these are mostly unsolvable by technical means. As the SWWG has produced technical specifications rather than a code of ethics or policy recommendations, its reach is somewhat limited.