Social Web in the Wild
Introduction
The previous chapter discusses an individual's relation with their online representation; how users understand profiles; how the affordances of a profile impact the culture of an online community, including how users interact and relate to each other, and how users understand themselves as part of the community. This chapter contains original studies; two which examine online profiles from an outside perspective, by looking at what systems offer and how individuals appear to be making use of this. Three of the studies go behind the scenes to actually ask profile owners about their participation in the social Web ecosystem.
Each study resulted in a small taxonomy useful for categorising the participants' experiences in each particular scenario. A core contribution of this thesis is to coalesce the results of these new studies, along with knowledge from existing literature, into an overall framework consisting of five concepts. This framework - the 5 Cs of Digital Personhood - constitutes the key components for describing online self-expression experiences. The framework is summarised here for reference, and I discuss its derivation in more detail in the conclusion of this chapter.
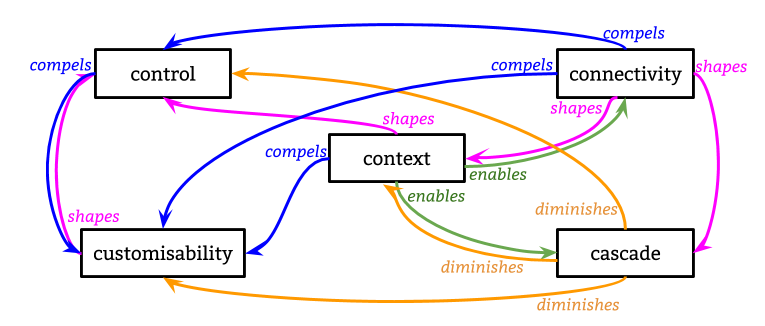
Each component encapsulates a variety of different parts or aspects which are revealed through the studies in this chapter, as well as prior research:
- Control: over persistence or ephmerality of identities, attachment or not to real names, traceability between different identities (eg. Can I delete my profile?).
- Customisability: of the data that is included in an online representation, the extent to which this is available to others, and how it is presented (eg. Can I change the name that appears on my profile?).
- Connectivity: to others and an audience, known or imagined, and how impressions by this audience can be managed (eg. Do I know how this profile appears to my mother?).
- Context: the social/cultural expectations of a platform or community; personal motivations and use cases; technical constraints of systems; offline cultural norms or biases which affect or constrain online behaviours (eg. Are the people who control this platform obliged to adhere to the same laws as I am?).
- Cascade: of personal information throughout a network, perhaps unknown; 'profiles' generated by algorithms, data passed around by third parties or collected through surveillance; expression 'given off' over which individuals have little knowledge or control (eg. Is my data being used to recommend products to me?).
Whilst all five components influence each other in complex and shifting ways, I illustrate key relations with the following terms:
- compels: the existence of aspects of one necessitates the involvement of aspects of the other.
- diminishes: aspects of one reduce the effect of aspects of the other.
- enables: aspects of one increase the effect of aspects of the other.
- shapes: aspects of one feed into aspects of the other; the latter is formed according to or depending on variations in the former.
Overview of studies
Table 1 summarises the methods, inputs and outputs of the five studies in this chapter.
The previous chapter established that there are various different (potentially overlapping) perspectives that need to be taken into account when discussing online self-presentation:
- Active users of a system, who maintain a profile.
- Passive users of a system, who may not have a profile of their own.
- System designers and developers, who must model and display data about their users.
- Third-party developers who build additional services using data from another system.
- Outside bodies which seek to influence or direct how systems are used for legal, ethical or economic reasons.
The five empirical studies in this chapter touch on each of these perspectives to some degree.
The first study sets a baseline for describing and categorising online profiles by asking the question "what is a profile?" and takes an objective look at 18 online systems which employ user profiles in a social capacity to classify their features. Subsequent studies focus on the people behind the profiles, or behind the systems themselves.
As hinted at in the previous chapter, individuals are rapidly and often intuitively developing coping mechanisms and practices to improve their handling of online self-presentation and impression management despite the constraints of the tools they use. The studies build on this background, first by observing system users from the outside (in the case of creative content producers on YouTube), and then by asking them questions and exploring their feelings and experiences with online profiles, with regards to: deception and lying on social media; imagining social systems as tools for mediating reality; and designing and building one's own customised social systems.
| Study | Type | Participants | Publication | Perspectives | Resulting terminology/themes |
|---|---|---|---|---|---|
| What is a profile? | Descriptive, observational | 18 | n/a | A S T | flexibility, access control, prominence, representation, portability |
| Constructing online identity | Empirical, observational | 10 | WWW14 | A | roles, attribution, accountability, traceability |
| The many dimensions of lying online | Survey | 500 | WebSci15 | A P S | system, authenticity, audience, safety, play, convenience |
| Computationally mediated pro-social deception | Interviews, design fictions | 15 | CHI16 | A P O | effort & complexity, strategies/channels, privacy & control, authenticity & personas, access & audience, social signalling & empowerment, ethics & morality |
| #ownYourData | Interviews | 15 | n/a | A S T O | self-expression, persistence/ephemerality, networks & audience, authority, consent |
| Perspectives: | A — Active users; P — Passive users; S — System developers; T — Third party developers; O — Outside bodies | ||||
| Publications: | WWW14: | Guy A. & Klein E. (2014) Constructed Identity and Social Machines: A Case Study in Creative Media Production. Proceedings of the 23rd International Conference Companion on World Wide Web - WWW'14 Companion. | |||
| WebSci15: | Van Kleek, M., Murray-Rust D., Guy A., Smith D., O'Hara K., & Shadbolt N. (2015). Self Curation, Social Partitioning, Escaping from Prejudice and Harassment: The Many Dimensions of Lying Online. Proceedings of the ACM Web Science Conference. 10:1-10:9. | ||||
| CHI16: | Van Kleek, M., Murray-Rust D., Guy A., O'Hara K., & Shadbolt N. (2016). Computationally Mediated Pro-Social Deception. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems. 552–563. | ||||
What is a profile?
This is a descriptive study of 18 systems which employ profiles in a social capacity. This study results in five features and each system is scored according to the degree each feature is present. Using these features we can cluster similar systems together, or differentiate them, and future studies can use these features to create baseline descriptions or characterisations of systems for comparison. The features are: flexibility, access control, prominence, portability, representation.
Introduction
In order to build on our understanding of the role an online profile plays in self-presentation, identity and interaction we need a more nuanced understanding of what a ‘profile’ is in a general sense. What is the meaning of profile? I carried out an empirical analysis of digital representations of users of 18 different online systems. From this analysis I derive a set of constructs to capture features of profiles in online systems. I propose this for assessing the benefits and drawbacks of how profiles are implemented in existing systems in such a way that takes into account the scenarios in which they are used, as well as groundwork for deriving requirements for profiles when designing new systems which need digital representations of their users. Once we have a characterisation of a particular type of profile a system enables, we can use these as control features when comparing systems side by side. Interesting future study would be to determine how the features of a profile influence actions of users or community formation, and vice versa.
For the purposes of this thesis, I define social systems to be Web-based networked publics which offer individuals consistent and reusable access to an account which they can personalise and use to interact in some form with others in the system.
Context and research questions
Profile generation is an explicit act of writing oneself into being in a digital environment (boyd, 2006 [boyd06])
boyd's definition of profile generation above is based on teenagers' use of Friendster and MySpace in 2006. Today, online social systems use profiles in a variety of different ways, and present them in a variety of configurations. Profile generation is not only explicit, but can occur implicitly, without necessarily even the consent or awareness of the profile subject. As discussed in the previous chapter, studies of online profiles tend to focus on oversimplifications or very specific (unrealistic) use cases, which do not take into account the broader system in which the profile exists. This approach often reduces an individual's representation in the system to a single document or webpage, and neglects the rich array of interactions and activities in which they engage in order to create a presence for themselves. In reality, profiles vary in how they are constructed and the roles they play.
This study serves to introduce a formal classification of profile features, and asks the following questions:
- What are common features of the ways users are represented in online social systems?
- How do these features vary between systems?
Kaplan & Haenlein (2010) categorise social systems into six groups [kaplan10]:
- Blogs are "special types of websites that usually display date-stamped entries in reverse chronological order"
- Social Networking Sites are "applications that enable users to connect by creating personal information profiles, inviting friends and colleagues to have access to those profiles, and sending ... messages between each other"
- Collaborative Projects "enable the joint and simultaneous creation of content by many end-users"
- Content Communities are for "the sharing of media content between users"
- Virtual Gaming Worlds are "platforms that replicate a three-dimensional environment in which users can appear in the form of personalized avatars and interact with each other ... according to strict rules in the context of a massively multiplayer online role-playing game (MMORPG)"
- Virtual Social Worlds "allows inhabitants to choose their behavior more freely ... there are no rules restricting the range of possible interactions"
The subjects of this study (see Table 2) are a cross section of these, but there are also some which do not fit into this framework. Since Kaplan & Haenlein's categorisation, (at least) two new types of system have emerged:
- Quantified Self: life-logging or self-tracking; automated or manual recording of minutiae of daily life;
- Transactional: networks that exist for exchange of goods or services.
Study Design
This is a descriptive study [#], which aims to gather and present information about the current state of social systems with regard to how their users are represented. I do not try to determine causal effects between features of systems, nor do I hypothesise about how these features impact users. Rather, I provide a characterisation of a set of systems as a foundation for future exploratory research.
Method
I started with the following areas to investigate:
- Data contained within a profile.
- How profile data may be accessed by others (within and outside of the originating system).
- How profile data may be distributed or pushed to others (within and outside of the originating system).
- The role of profile data within the broader system.
The starting point for a 'profile' was typically a unique identifier for an entity (which could be an individual or group) such as a URL or username. After initial explorations of the profiles in a few systems, these areas were refined into specific questions:
- What does a profile contain?
- How are profiles within a system connected together?
- How are profiles updated?
- How are people notified when a profile is updated?
- How is access to a profile controlled?
- How can profiles be exported from or imported into a system?
- What constraints are placed on a profile?
- How do profiles fit in with a systems apparent data model?
- What is the profile for?
- Who is the profile for?
I took one system at a time, and answered all of the questions by logging in (where applicable) to my own account and observing the behaviours of the system in response to interactions with my own and other users' profiles (where necessary), and took screenshots. I also read systems' terms of service, "About" pages, introductory descriptions or statements of purpose, and leaned on my own background knowledge of how the systems are used by myself and others.
Having answered all of the questions about each system, I passed through each one again to confirm, and add more detail if necessary, and I noted similarities and differences between systems. From the results, I derived a set of potential features for profiles, and ranked each system according to the presence of features. This allowed some clustering of similar systems into a general categorisation framework.
Subjects
18 social systems were selected for the initial analysis phase. Most are ordinary websites which one uses by registering, then logging in and out. Some include or require self-hosted software.
Popular systems which I have personal experience were chosen, in order to take advantage of latent background knowledge when navigating the systems.
The information in Table 2 serves to give a feel for the diversity of the social systems being studied.
| System | URL | Type | Specialisation | Overview | Categoryk | |
|---|---|---|---|---|---|---|
| AirBnb | airbnb.com | website | travelers | Accommodation renting | T | |
| CouchSurfing | couchsurfing.com | website | travelers | Accommodation, cultural exchange, new connections | T | |
| facebook.com | website | general | New and existing connections | SNS | ||
| Friendica | friendi.ca | website / software | general | New and existing connections | SNS | |
| Github | github.com | website | developers | Collaborate on software | CP | |
| Indieweb wiki | indieweb.org | website | developers | Collaborate on ways to develop social web presence | B, CP | |
| linkedin.com | website | professional | New and existing connections | SNS | ||
| OkCupid | okcupid.com | website | relationships | New connections | SNS | |
| PeoplePerHour | peopleperhour.com | website | professional | Hiring freelancers | T | |
| Pump.io | pump.io | website / software | general | New and existing connections | SNS | |
| Quora | quora.com | website | general | Q&A (any topic) | CC | |
| ResearchGate | researchgate.net | website | academic | Advertise/find research publications | CC | |
| RunKeeper | runkeeper.com | website | sports | Track sporting activities | QS, CC | |
| StackOverflow | stackoverflow.com | website | developers | Q&A (tech) | CC | |
| Tumblr | tumblr.com | website | general | New and existing connections | CC, SNS, B | |
| twitter.com | website | general | New and existing connections | B, SNS, CC | ||
| YouTube | youtube.com | website | general | Consume/create media | CC | |
| Zooniverse | zooniverse.org | website | science | Citizen science | CP | |
| Categories from Kaplan & Haenlein: B — Blog (including Microblog); SNS — Social Networking Site; CP — Collaborative Project; CC — Content Communities | ||||||
| Additional: QS — Quantified Self; T — Transactional | ||||||
Limitations
As with everything in this thesis, this study is limited by a Western, English-speaking perspective on the systems in question. The observations were conducted from an IP address in either the UK or the US, and I did not attempt to find out how each system differs based on the language preferences or geographical location of users.
Significantly these systems change over time, often rapidly, in response to changing markets, legislation, and available technologies. Most of the data was collected and screenshots captured in the summer of 2015. Some data points were verified to be largely in line with the original findings, but not deeply verified, during writeup in spring 2017. It is important to note that the results are a dated snapshot which cannot be assumed to hold true indefinitely.
I will emphasise again that the nature of a descriptive study does not give any indication of cause-effect relationships between any of the results. Similarly, I can only describe systems as they appear, and not speculate as to why they appear such.
Results
Here I summarise the findings of the study.
The most distinct of the systems is the Indieweb wiki, which largely functions as an ordinary wiki except that one identifies oneself with a domain name (logging in with the IndieAuth authentication protocol) and thus the 'profile' is tied to one's personal blog, website, or homepage. As a result, profiles are highly custom and diverse; even though they are not hosted centrally by the wiki software they are the main source of identification between users of the wiki, so they are considered here in the same way as the profiles in other systems. In order to study them without visiting the domains of every single user, I also make use of the contents of the wiki itself, which is focused around documenting and recommending best practices for creating a social Web presence; that is, I assume that practices relevant to profile creation described the wiki are adopted by a majority of users.
What does a profile contain?
Profiles contain some combination of: attributes (key-value pairs of data); content (text or media) created by the profile owner; a list of activities or interactions the profile owner has carried out in the system; links to profiles with which they are connected; links to content the profile owner has interacted with (e.g. 'likes'); links to collections of content curated by the profile owner; statistics about the profile (e.g. 'member since'); automatically generated rankings or ratings of the profile owner; reviews, messages or content left by other members of the network.
All of the 18 systems use attributes in the profile, and none use only attributes. Attributes may be generic (such as name, bio, location), as well as tailored to the specific system (countries I've visited on CouchSurfing; knows about on Quora; looking for on OkCupid). Some attribute values are offered as a fixed set to choose from, and others permit free-text input. Some systems may require a minimum input of certain attributes, and some leave everything entirely optional.
Facebook has the broadest array of possible attributes, including the possibility to create your own keys, and use ones that others have created. CouchSurfing and OkCupid make extensive use of free text input, prompting users to write short essay-style answers to certain questions. Most systems encourage an avatar or display picture, and several also permit uploading a prominent header image (also known as 'banner' or 'cover photo'). The Indieweb community bases attribute-style profile content around the microformats h-card specifications, which provides a fixed set, all optional.
Indieweb profiles tend to be the homepages of blogs (although they may be a more static 'about' page) and are heavy on the content and activities aspects. SNS like Twitter, Facebook, Tumblr, Pump.io and Friendica, also lend prominence to content (typically text-based status updates; often photos) and a feed of activities on the site. YouTube incorporates videos created by the profile owner, and how these are organised is highly customisable. For users who have not uploaded video, YouTube profiles contain mostly attributes and activities, and elevate interactions with other content on the site, such as commenting on videos, adding to playlists, and subscribing to channels.
Activity feeds in general vary in their level of detail. Quora displays if someone edited a question or answer. Pump.io distinguishes between 'major' and 'minor' activities, displaying them in separate feeds. Mixed in with posts by the profile owner, Twitter includes a heavily algorithmically curated subset of activities, such as recent follows or likes. Most sites do not include a complete log of all of the possible interactions however. For example, CouchSurfing enables a rich array of activities, from offering to host a guest, to posting in group forums and arranging events; but none of these are displayed on a user's profile. Similarly, most systems do not display a feed of changes to attributes of the profile, which could also be considered activities.
On the other hand, when users interact with content on a system, for example by liking or favouriting it or adding it to a collection (a playlist on YouTube), reblogging it on Tumblr, voting on it on Quora or StackOverflow; this content becomes part of the profile.
StackOverflow, GitHub, PeoplePerHour, ResearchGate, Quora and RunKeeper are very statistics-oriented. RunKeeper focusses on a feed of offline activities, calculating for example how many calories you lost this week from logged exercise, or how far you ran. GitHub visualises code commits and 'contributions' (helpful interactions with projects) in a coloured grid. ResearchGate and Quora display statistics about how much others have interacted with the profile owner's content. OkCupid also generates statistics based on answers to short, multiple-choice personal questions, and these statistics are dependent on who is viewing the profile, e.g. percentage romantic match, and things like '30% more social'.
Sites which make heavy use of content left by others on a profile are CouchSurfing, AirBnB, and PeoplePerHour. Each of these display reviews of the profile owner by other users, typically in a way that cannot be amended or removed. Facebook allows one to 'write on the wall' of another profile, but users can disable this. However, comments and likes by other users commonly show up alongside activities or created content on a profile as well. LinkedIn prompts users to 'endorse' one another for particular skills, and these endorsements are prominent on profiles. StackOverflow and Quora aggregate ratings left by others on content into overall numbers or rankings to display on profiles.
Many systems give prominence to the connections with other users in the system; LinkedIn displays neither likes nor status updates on the profile, but emphasises contacts and the network around them; Twitter displays followers and following; YouTube, ResearchGate, Pump.io, Friendica, and Quora display subscriptions and subscribers.
How are profiles within a system connected together?
Connections between profiles may be uni- or bi-directional; some systems permit both. Bi-directional connections need to be mutual; triggered by one user and confirmed by the second. Uni-directional connections may or may not need approval from the second user, depending on either the system as a whole or individual user preferences. Some systems contain more than one kind of uni-directional connection, which may be named or displayed differently, and carry different connotations. Systems vary in whether or not they notify other users (than the ones involved in the connection) about new connections.
Systems with uni-directional connections are Twitter, Tumblr, Pump.io, Facebook, Quora, LinkedIn, ResearchGate, Friendca and GitHub ('follow'), YouTube ('subscribe'), OkCupid, PeoplePerHour ('like/bookmark/favourite'). Systems with bi-directional connections are CouchSurfing, Facbook, Friendica, and RunKeeper ('friends'), LinkedIn ('connect'). The intersection of these (systems with both) is Facebook, LinkedIn, and Friendica.
Some Indieweb profiles include a list of others the profile owner follows using XFN markup [xfn], but this is not necessarily widespread. StackOverflow, Zooniverse and AirBnb do not have a means of creating persistent connections between profiles, besides leaving references in the case of AirBnb.
Systems which permit more specific information or categorisation of connections are CouchSurfing (specify 'hosted', 'surfed', 'traveled with' or 'never met' as well as the closeness of the relationship), and Facebook (can specify specific relationships, e.g. 'brother'). When a follow request is sent on Friendica, the recipient can accept it as uni-directional (the follower is labelled a 'fan/admirer') or bi-directional, so the recipient also sees the follower's updates. Bi-directional connections on LinkedIn require a reason or more information as 'proof' of a mutual connection, before the request is even sent.
YouTube connects profiles together through subscriptions to channels, however it also explicitly provides input for profile owners to link to other profiles without creating a subscriber relationship. This lets content creators list, for example, other users they admire, or the people they collaborate with. Many YouTubers use this feature to link to other profiles they have on the site. The system gives users free text fields to name this list, as well as each individual link in the list. This particular phenomenon is examined in more detail in the next study, Constructing Online Identity.
OkCupid connections are uni-directional, and only revealed to the recipient if and when a mutual action is made. On Twitter, following another user sometimes (not consistently) appears as an activity in your timeline; notifications are also sometimes sent to your followers to advertise the new connection.
How are profiles updated?
Profiles may be updated by profile owners via a system's user interface, programmatically through an API (Application Programming Interface; the means through which data can be read or written by third-party software). The latter is relevant because programmatic access suggests that third-party applications (outside of direct control the system itself) can also influence a profile owner's view on the possibilities of the profile.
Most systems provide a Web form to add or update attributes, or a similar UI in a native mobile application. The editing interface and the profile display may be tightly coupled (Twitter, Quora, LinkedIn, ResearchGate) completely divorced, or a combination (Facebook, OkCupid). Indieweb profiles are updated with custom editing interfaces, or simply by editing static HTML; there are currently no specific recommendations for protocols or UIs to edit profile attributes.
For the non-attribute data which makes up a profile, separate, often specialised interfaces for both Web and mobile exist, e.g. for posting status updates or media content. For data like statistics and activities, this content is generated by algorithms or sensors, with no explicit input from the profile owner. In a few cases it may be hidden by the profile owner, but rarely changed. An exception is RunKeeper, where one can edit an automatically generated GPS trace after the fact, which can correct distance and speed records. On CouchSurfing, AirBnB and PeoplePerHour, one may respond to a review left by someone else, but not remove it.
Only Pump.io, RunKeeper and GitHub provide APIs to update all attributes of a profile. Facebook and Zooniverse provide limited update access to certain attributes. Most systems provide write APIs to create, follow and like (or equivalent) non-attribute content.
How are people notified when a profile is updated?
The attention a system draws to profile updates could affect how people engage with their own profiles. When profile attributes are updated by the profile owner, most systems do not notify other users of the system at all.
Facebook however pushes updates to friends' timelines along with status updates and content interactions, though the extent to which it does this for each friend depends on their arbitrary content distribution algorithm, and from a user perspective is hard to predict. The most reliably seen attribute updates are changes to profile pictures, cover photos, and relationship status. Whenever the profile owner updates an attribute on Facebook, they are asked to make it a 'story', which sustains a reference to the fact the attribute changed. Friendica notifies about changes to profile pictures only.
OkCupid and LinkedIn provide the option to enable sharing of changes to profile attributes. In the case of LinkedIn, updates are pushed to contacts' feeds, but may also be displayed to non-immediate contacts in the network as a form of promoting connections. OkCupid may display updates to other users in their activity feeds according to whether the system thinks these people might be interested in your profile. How either of these are decided is opaque to the user.
How is access to a profile controlled?
Systems may provide all-or-nothing access to profiles, make everything public but all optional, provide access control on the basis of groups or networks, or individual users, and provide granular access to individual aspects of profiles.
Systems which have limited or no access control, but make all or most data optional to enter include OkCupid, Quora, CouchSurfing, AirBnB, Friendica, Zooniverse, Pump.io and GitHub. OkCupid and CouchSurfing allow profile visibility to be restricted to other logged-in users. CouchSurfing permits users to hide their full name, and GitHub permits users to hide their email address.
Quora permits users to answer or ask questions as 'anonymous' whilst logged into their account. These questions/answers do not show up on the user's profile. Otherwise, the only other control profile owners have is disabling their online presence. Friendica permits connections to be hidden, as well as certain aspects of content. On AirBnB, profile attributes are optional but hosts can automatically decline users who omit certain attributes.
Systems with more granular concepts of audience than public/private include Pump.io, LinkedIn, Facebook, Twitter, and ResearchGate. In Pump.io individual objects can be 'addressed' so that only particular groups (which can be created by the profile owner) or individuals can see them. LinkedIn permits visibility of some individual profile attributes to 'everyone', 'my network' and 'my connections'. The profile can be set to publicly visible, with certain attributes individually excluded. Connections can be private or public, and content and interactions can be designated different levels of visibility from entirely private to entirely public, with 'network' and 'connections' in between. ResearchGate enables hiding certain statistics, certain attributes, and certain content. Uploaded papers can be visible to 'everyone', 'mutual followers' or 'ResearchGate members'.
Twitter allows users to 'protect' their profiles, which means only those requesting access can see content and connections; however, all attributes are visible to anyone regardless. Profile owners can block other users, preventing them from seeing everything but their name, display picture and profile banner.
Systems with granular access control across several different aspects of the profile include YouTube, Facebook, RunKeeper and ResearchGate. YouTube provides granular access controls for various attributes, interactions, links to content, some statistics (like number of subscriptions) and content. RunKeeper attributes can be assigned levels of visibility individually ('everyone', 'friends', 'just me').
Facebook has complex granular access controls, including individual attributes, content, interactions, connections and links. Defaults can be set, as well as updated on a per-object basis at the time of posting/creating. Content can be restricted to include or exclude individuals, groups, particular networks. Read and write access controls are distinct; that is, one can create a post that is publicly readable, but comments on that post may be restricted or disabled completely.
Tumblr's use of 'primary' and 'secondary' blogs is interesting; where a blog constitutes a profile, users can essentially have as many profiles as they want attached to one login. Primary blogs (one per login) are always public, but secondary blogs (unlimited) can be password protected. There are no automatic links between a user's primary blog and secondary ones, including through the API. There is also no way to tell if a particular profile is primary or secondary, or the account to which a secondary blog is attached. Secondary blog owners may also grant write access to other system users, enabling multi-user profiles. Blocking users prevents the blocked user from interacting with or seeing content.
How can profiles be exported from or imported into a system?
In the Indieweb model of profile ownership, all data is assumed to be on a server controlled, or at least trusted, by the profile owner. As such, they can move it however they please. Similarly, Pump.io and Friendica are open source software platforms which allow people to either opt to use an instance on a server they trust, or install their own instance for complete control. They both use the standard ActivityStreams 1.0 data model [as1] (Friendica has extensions); while Friendica provides import/export functionality in the UI, Pump.io doesn't, however the database or JSON feed is compatible across instances.
Twitter, Facebook, YouTube, LinkedIn, ResearchGate, and RunKeeper provide a download link for an archive of content. In most cases these are a snapshot of current profile attributes, without a history of changes, except for Facebook, which provides a comprehensive activity log. All exports are proprietary schema in JSON, HTML or CSV.
StackOverflow profiles are reusable across different StackExchange sites; there is no export, however there are public dumps of Q&A data. GitHub data is available through an API.
Tumblr, CouchSurfing, Quora, OkCupid, PeoplePerHour, AirBnB and Zooniverse provide neither an export nor an API to access all profile data.
What constraints are placed on a profile?
In this section I examine the terms of service of systems to determine how users are expected to engage. In some cases these are enforced by technical constraints.
Twitter, CouchSurfing, Facebook, OkCupid, LinkedIn, PeoplePerHour, AirBnB and GitHub state that a user may not have multiple accounts. Twitter qualifies this with "overlapping use cases".
Tumblr users cannot create two primary blogs with the same email address, and can create 10 secondary blogs per day on the same login with no overall limit. Secondary blogs are somewhat constrained in their functionality compared to primary blogs.
Couchsuring, Facebook, Quora, StackOverflow, LinkedIn, PeoplePerHour, AirBnB, GitHub and RunKeeper explicitly disallow 'fake' profiles; the profile owner must be a single 'real' person, and not be impersonating someone else.
What is the data model of a profile?
To answer this question, I have examined wording in systems' documentation around profiles, in user interfaces as well as APIs. Where possible, I have also looked at internal data models of the software.
Accounts and people are roughly equivalent for Twitter, Indieweb, Pump.io, LinkedIn, Facebook, Quora, PeoplePerHour, ResearchGate, OkCupid, AirBnB, Zooniverse, RunKeeper, and GitHub profiles. That is, a profile sufficiently identifies a person; for example the "name" attribute of a profile is the name of the profile owner (rather than the name of the profile). Activities associated with these profiles (e.g. "distance ran" or "commit made") are assumed to have been carried out by the profile owner.
Tumblr and YouTube equate an account - or username/password combination - with a person, but each account may be attached to multiple profiles: secondary blogs in the case of Tumblr, channels in the case of YouTube. Profile owners can carry out interactions from behind one of these profiles at a time.
Friendica permits a user of one account to create multiple profiles with different attributes, and set up access control so that certain people see a particular profile. Different profiles are different 'views' on one person. Profile owners can also assign a 'type' to their profile which automatically sets some defaults for privacy and access control settings.
What is the profile for?
This question looks at the purpose of the profile within the system, rather than any purpose of the system itself, though the two may be similar.
In Twitter, Tumblr, YouTube, Quora, StackOverflow, Indieweb, ResearchGate, Zooniverse, RunKeeper and Github, profiles serve as a central hub for aggregation of content by the profile owner. In the cases of Twitter, Tumblr, Pump.io, CouchSurfing, Facebook, LinkedIn and Friendica, a profile serves as an endpoint for connections and relationships within networks where connections are important.
In systems with high levels of interaction and often some concern about trust or reputation, profiles provide a face behind content so that statements may be evaluated against the backdrop of 'who said it' (e.g. Twitter, Tumblr, Pump.io, YouTube, CouchSurfing, Facebook, Quora, StackOverflow, ResearchGate, Friendica, Github). Systems which are particularly geared towards building trust or reputation as a foundation for future relationships and interactions within the system are CouchSurfing, Quora, AirBnB, OkCupid, StackOverflow, LinkedIn, PeoplePerHour, ResearchGate and Zooniverse.
Profiles which are geared particularly towards self-expression, or establishing a presence, are Indieweb, Twitter, Tumblr, Facebook, Pump.io, YouTube and Friendica.
Who is the profile for?
Often who a profile is intended for is related to the profile's purpose within the system. In some cases, the audience is known (e.g. you know who follows you on Twitter; Tumblr, Pump.io, YouTube, Facebook, Quora, LinkedIn, Friendica, RunKeeper, Github) and in other cases imagined (you have an idea of who OkCupid might be promoting your profile too, but no sure evidence; the same for CouchSurfing, StackOverflow, Indieweb, PeoplePerHour, ResearchGate, Zooniverse) and in some cases both (your Twitter profile is public, so people who aren't your followers will see it; also similar for Tumblr, Pump.io, Facebook, Quora, LinkedIn, Friendica, RunKeeper, Github).
In cases where a profile is constituted of an aggregation of personal data, content, and online interactions, the profile owner is a member of the audience, as they can use it for self-reflection or self-expression (Twitter, Tumblr, Pump.io, YouTube, Facebook, Quora, OkCupid, Indieweb, StackOverflow, LinkedIn, ResearchGate, Friendica, RunKeeper, Github).
Systems like Quora, CouchSurfing, OkCupid, StackOverflow, LinkedIn, PeoplePerHour, Twitter, Facebook, YouTube and AirBnb use data from user profiles as input to core algorithms which enable the system to function, providing a service to profile owners.
Similarly, systems such as Twitter, Facebook, Tumblr, YouTube, CouchSurfing, LinkedIn and RunKeeper use profiles as input to algorithms which sustain the companies behind the systems, for example through selling data to third-parties like advertisers.
Features
From this analysis, five features of profiles were derived and are described below, and summarised in Table 3.
| Feature | Strongly applies (1) | Does not apply (0) |
|---|---|---|
| Flexibility | Profile owners have choice about the kinds of content associated with their profile and how it is presented. | Profiles are generated as a side effect of owner's activities or automatically (e.g. from sensor data) and owners cannot amend. |
| Access control | Profile owners have control over which parts of the profile others see. | Profile owners have no control over what others see. |
| Prominence | Profiles are integral to functioning of the system as a whole. | Profiles are a side-effect of some other function of the system, and/or not necessary to use the system. |
| Portability | Profile owners can move their data in or out of a system. | Profile data cannot be imported or exported. |
| Representation | The profile is a person, as far as the system is concerned. | The profile is a document describing some aspect of a person(a). |
Flexibility is a function of the different types of content/data which make up a profile, and the relationship the profile owner has with those who see or use their profile. As some times of content are under more control of the profile owner than others, we consider the proportion to which they make up the profile, and weighting given to each. Flexibility also considers the systems technical or policy constraints around profile contents.
Access control involves the granularity of the controls, the extent to which profile owners can opt into or out of publishing certain aspects, and the awareness of the owner of who their audience is.
Prominence takes into account the extent to which a system would function were users' data (of the various kinds) not aggregated into profiles. Prominence of profiles may depend on the role a user is playing in the system, so the potential varying roles are also taken into account. Systems with a high emphasis on connecting people feature profiles prominently, whilst systems with lots of interactions but little need for reputation do not necessarily require consistent profiles to be useful.
Portability considers how easy it is to get profile data out of a system, as well as how reusable that data is in other systems. This includes whether data is exported into a known standard data model, and standard file format, and the extent of additional processing that may be required to port it elsewhere.
Representation connects the systems' model of users with its purpose. Systems with the possibility or expectation of personas or partial representations of individuals are not considered representative, whilst systems with emphasis on 'real people' and one-to-one mappings between profiles and profile owners have high representation. Systems in which the real-life human is required for legal or transactional purposes (e.g. to make a payment or provide a service) make a distinction between the profile and the person, and this lowers representation.
An overview of the questions which contributed to the derivation of each feature is in this table and the rankings of each system against each feature are in the following table.
| Feature | Questions | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Flexibility | X | X | X | X | X | X | ||||
| Access Control | X | X | X | X | ||||||
| Prominence | X | X | X | X | X | |||||
| Portability | X | X | ||||||||
| Representation | X | X | X | X | ||||||
| System | Flexibility | Access Control | Prominence | Portability | Representation |
|---|---|---|---|---|---|
| AirBnB | 0.2 | 0.2 | 1.0 | 0.0 | 0.9 |
| CouchSurfing | 0.5 | 0.1 | 1.0 | 0.0 | 0.9 |
| 0.3 | 0.9 | 0.7 | 0.5 | 0.8 | |
| Friendica | 0.8 | 0.8 | 0.7 | 1.0 | 0.2 |
| Github | 0.2 | 0.1 | 0.3 | 0.4 | 0.8 |
| Indieweb wiki | 1.0 | 0.0 | 0.5 | 1.0 | 1.0 |
| 0.3 | 0.8 | 0.8 | 0.5 | 0.9 | |
| OkCupid | 0.5 | 0.1 | 1.0 | 0.0 | 0.7 |
| PeoplePerHour | 0.5 | 0.1 | 1.0 | 0.0 | 0.9 |
| Pump.io | 0.8 | 0.2 | 0.7 | 1.0 | 0.5 |
| Quora | 0.5 | 0.2 | 0.3 | 0.0 | 0.9 |
| ResearchGate | 0.6 | 0.4 | 0.3 | 0.8 | 0.9 |
| RunKeeper | 0.7 | 0.5 | 0.1 | 0.5 | 0.4 |
| StackOverflow | 0.5 | 0.1 | 0.3 | 0.3 | 0.9 |
| Tumblr | 0.8 | 0.7 | 0.2 | 0.0 | 0.1 |
| 0.6 | 0.5 | 0.2 | 0.4 | 0.5 | |
| YouTube | 0.7 | 0.7 | 0.2 | 0.7 | 0.5 |
| Zooniverse | 0.5 | 0.1 | 0.1 | 0.0 | 0.8 |
Discussion
Five features of online profiles were derived from observations of the functionality and uses of a set of existing social systems. We can use these features to cluster similar systems and give us a better understanding of online profiles in the social web ecosystem today. In this section I discuss some noticeable clusters. When I use 'highly' in reference to a score, I mean the score was greater than 0.5.
Though much of the literature around studying user profiles only acknowledges attributes [dcent, counts09] we can see that profiles are constituted of much more than just descriptive attributes about an individual. Content that makes up a person's profile may be input directly by the profile owner, generated or inferred from their online or offline activities, combined with content of others in the system and/or generated directly by other users of the system. Different systems emphasise different aspects of a person's online presence and allow users to adjust this to varying degrees.
The features which enable greatest control over self-representation for users are flexibility, portability and access control. Flexibility means that users have freedom to choose which information and contents make up their profile; portability means that they can move this data around or repurpose it easily; and access control means that the profile owner can choose who sees what. These things in combination are particularly empowering. Thus, the systems which give users the greatest control are Friendica and YouTube, which score highly for all three, and Tumblr, which scores highly for flexibility and access control. To a lesser degree, Pump.io, Indieweb and ResearchGate score highly for flexibility and portability, but with limited access control. This means that profile owners must employ strategies of omission or self-censorship to effectively manage what their audience sees. Facebook and LinkedIn on the other hand score very highly for access control, but lower for flexibility and portability; that is, you don't have much control over how your profile is constructed, but at least you can control who sees the information.
Systems with high prominence scores tend to also have high representation scores. However Friendica has a very high score for prominence, as profiles are crucial in a network where making connections is the end goal, but it has a low score for representation, as the expectation is that profile owners present personas, and may have more than one for different aspects of themselves. The high-prominence and high-representation systems (CouchSurfing, PeoplePerHour, AirBnB, OkCupid, Facebook, LinkedIn) have strong ties to 'real life', for example in-person meetings, employment, or service exchange.
Low prominence systems are geared towards an end purpose that is not oriented around user profiles, such as content creation, collaborative projects or information aggregation (Zooniverse, YouTube, Twitter, Quora, StackOverflow, ResearchGate, Github, Tumblr, RunKeeper). Profiles are useful, but not an end in themselves. On top of being low prominence, Tumblr and RunKeeper are not very representative; Tumblr permits multiple profiles and the community generally expects anonymity or pseudonymity; RunKeeper contains a very small subset of information about a person. Zooniverse, StackOverflow, Quora and Github nonetheless score relatively highly for representation, since unique profiles for individuals is necessary for establishing reputation or standing, a key element in these communities.
To be able to classify systems according to these features it is necessary to consider multiple perspectives: those of the profile owner, others who will see the profile, and the organisation which runs the system itself. As such, the classification process gives a holistic view of a system, but only at a surface level. It misses out on the finer details of how the system is situated in the context of a society, how profile owners use one system alongside others, and the multiple possible uses of a system by different people, or different roles people may play. Nonetheless this provides a baseline idea of how people could use a system, in order to carry out more detailed studies about how individuals actually do use a system.
In particular, in future studies of users of a particular system, researchers can refer back to the features of the system (perhaps scoring systems which have not been covered here, or updating scores for ones which have changed) in order to put the users' actions in the bigger picture.
Throughout the remaining studies in this chapter, where specific systems are highlighted, I refer back to these features.
Contributions to the 5Cs
Different systems require different levels of engagement with one's own profile. The prominence of a profile within a system, as well as how representative a profile is (or should be according to system rules) of its owner indicate that individuals may have different levels of control over their self-presentation. Relatedly, if one can take all of one's data out of a system and even move it elsewhere (portability), this may influence decisions about persisting or maintaining profiles.
Systems may be flexible about what data appears in a profile, how that data is presented, and how it is accessed by other users. I consider both of these features to contribute towards the customisability of self-presentation.
Access control and flexibility both indicate an awareness of the profile owner's audience. These, along with the prominence of a profile within a system, indicate that we must pay attention to the links between participants within a system, or the connectivity.
Users of systems are affected by both technical and policy constraints in terms of flexibility and portability of their profiles. The purpose of the system itself also influences the prominence and representation of profiles. These outside constraints and goals constitute the context formed by a system, as well as being influenced by the overall context in which a system exists (eg. legal frameworks, business interests).
Representation and access control together can drive or inhibit linkability between profiles in different systems, and offline identities. The spread and aggregation of information about an individual, possibly without their knowledge or consent, is part of the cascade of information beyond where it originated.
Constructing online identity
In the previous study we took a high level look at 18 social systems; in this study, we zoom in on one of them — YouTube. According to the previous study, YouTube channels are relatively flexible, access controlled, and portable, but not very representative, and even less prominent. Users participate in different roles on YouTube, from passive, possibly anonymous consumption, to engaged consumption with comments, interactions and curating playlists, to active content creation. The latter group also vary the level to which they participate; some users spontaneously or casually post videos for a small localised audience; some engage across multiple channels, manage branding, collaborate, nurture a fanbase, and create videos on a professional level.
The high flexibility and low prominence of YouTube profiles gives users a chance to be creative when expressing their identities. The following study empirically examines some different ways identities are expressed through YouTube channels, including a closer look at the affordances of the system and how individuals work within and outside of these.
Whilst YouTube is at the core of the online presences of the subjects of this study, their activities span a variety of other systems, not wanting to fall into the trap of imagining a system exists in isolation, I discuss these as well.
I identify four concepts that are useful for understanding individuals in a system with flexible self-presentation opportunities: roles, attribution, accountability, traceability.
This section has been adapted from work published as Constructed Identity and Social Machines: A Case Study in Creative Media Production (2014, Proceedings of WWW, Seoul).
Introduction
In chapter 2 I described existing work in understanding socio-technical systems as social machines. Due to the complex nature of online identity, understanding nuanced identity behaviours of social machine participants in a more granular way is crucial. First I will briefly describe creative media production social machines, then present the results of a study of profiles portrayed by participants in one of these. The contribution is a set of dimensions along which a social machine can be classified in order to better understand human participants as individuals, as opposed to participants in aggregate.
Amongst the plethora of user-generated content on the web are a huge number of works of creative media, and behind these are independent content creators pushing their work to a global audience and actively seeking to further their reach. Within this ecosystem we can see creative media production social machines on a variety of different scales. The definition of creative media production social machines encompasses a class of systems where:
- humans may use a purely digital, or combination of digital and analogue methods, and a degree of creative effort, to produce media content;
- the content is published to be publicly accessible on the web;
- a global audience may consume, curate and comment on this content in technologically-mediated environments.
These social machines exist both within and across content host platforms (e.g. YouTube) and within and across online communities and social networks. Many, if not all, media types and genres are represented among the media artefacts that emerge from these systems, and the content and the reception it receives can have a sometimes profound effect on media and culture in the offline world.
Figure 2 shows the interconnected social and technical systems engaged when a simple vlog (video blog) is uploaded to YouTube. These processes would be further expanded if the creator was to branch out and produce different types of content, collaborate with another creator, cross-publicise, share audiences or even co-own a YouTube channel or other website profile.
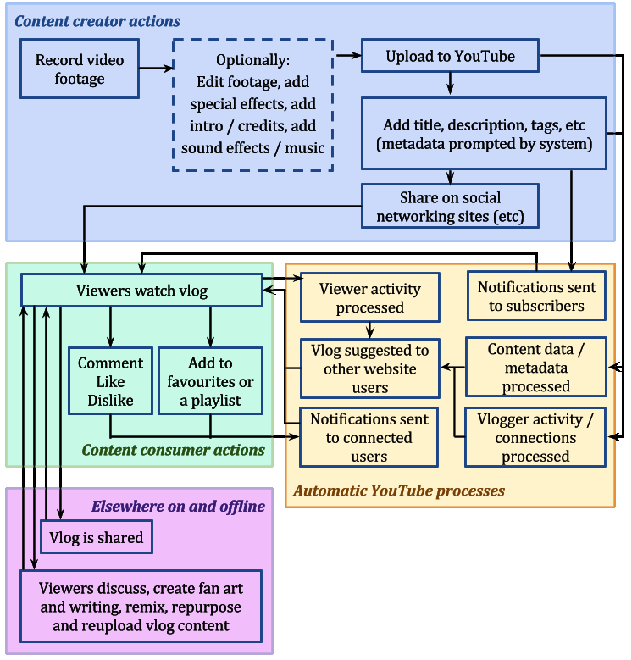
Creative media production social machines create an environment in which content creators of all backgrounds and abilities are able to publish outside the constraints of traditional media channels. These creators are actively vying for attention from massive audiences; competing for views, likes and shares on a global scale. How they present themselves to their audience can be critical to their success, but also a ground for playful experimentation.
Motivations for participation
It is worth noting that there are a variety of motivations or incentives for content creators to participate in creative media production social machines.
Some content host sites provide direct financial incentive for popularity (e.g. YouTube's Google Adsense). Others facilitate a commission based model, where creators show off their work and take paid requests for custom pieces from the community (e.g. DeviantArt). For content creators who publish primarily on such systems, their activity on other systems is usually tied to driving traffic back to the content which makes them money, or entertaining the fanbase from whom they thrive (e.g. a creator who publishes sketch comedy on YouTube might use their Twitter account to tell original jokes to maintain interest between video releases).
But for many content creators, the financial rewards from their chosen content host sites might be a convenient side-effect of doing something that they love. Reputation as a creator of high quality content, as a talented artist or as a particularly funny comedian might be their primary driver. There are also social cues in many communities that affect content creator behaviour. Sometimes creators don't want to be accused of 'pandering' to their audience or losing their artistic integrity, and regulate their behaviour accordingly.
The visibility of quantitative data collected by a content host site – such as how many views a piece of content has, how often a participant is referred to as a co-creator, or how often a participant responds to viewer comments – may also impact behaviour. Technical factors are often highly conflated with the social norms in a community.
Thus, the core reasons for creating content can affect both the content created and how creators present themselves to their audience in the process.
Context and research questions
To recap some background from chapter 2, the nature of identity and anonymity in online spaces is well discussed [Donath2002, Halpin2006, Rains2007, Ren2012]. Humans naturally adjust the way they present themselves according to the context, and different online spaces may afford different levels of flexibility in doing this. Systems which don't require any kind of registration to post content, allow people to adopt and discard personas as needed, and to create social cues to identify each other that are not designed as part of the system [Bernstein2011]. Entirely different behaviour occurs in systems that strongly encourage or even try to enforce usage of real names. Often it is trivial for people to create multiple accounts under different pseudonyms anyway, but there may be an increased expectation of honesty from other users of the system, which itself affects the culture of communities within.
In many cases the fact that people present themselves differently in different contexts is unconscious; a side effect of their participation in a particular system according to the social norms or even technical affordances (e.g. their desired username may be unavailable resulting in the forging of new branding around an alternative). In other cases, the creation of alternative personas is engineered and deliberate, either from the outset or as something that has evolved over time. Multiple individuals may also participate in the portrayal of a single persona [Dalton2013] and one individual may present versions of themselves through multiple personas.
The public profiles of content creators were examined with the following questions in mind:
- How do content creators present themselves within and across communities?
- To what extent are content creators' online presences consistent across platforms, and how is their content distributed across different online presences?
- How, and to what extent, do content creators present connections between their own online presences?
To add depth, I also take note of their audience, the type of content they create, and the capabilities of the platforms on which they publish their content.
Study design
This is an in-depth empirical study in which publicly visible data about individual social media users are analysed. The data includes content created by the subjects, attributes from their profiles, and links between profiles. We use only human-led, in-browser exploration of the profiles, and employ no scripts or API access to gather data.
Method
I first familiarised myself with the different ways of updating and modifying the data that appears on a YouTube profile (also known as a channel), so I could understand the actions that profile owners had to undertake to build their presence on YouTube.
The starting point for data collection was a particular YouTube channel per subject. The different types of profile information that were present were noted. Links from the profile content were gathered, and ones which were determined to connect to other profiles, within and outside of YouTube, were followed. The information on these profiles was similarly logged. I collected:
- The types of profile data visible.
- The number of inbound and outbound connections to other profiles.
- What kinds of other profiles belonging to the channel owner were linked to from a YouTube channel.
- How these links were labelled or described.
- How the data on these additional profiles differed from or overlapped with each other.
Subjects
Ten content creators were selected from a subset of creators with whose content I have a passing familiarity through encountering it online over prior months to years. This resulted in a broad spectrum of content types (video, animation, music, art, written word) genres (comedy, game commentaries, educational, political), popularity, well-knownness and activity levels. I deliberately examined content creator profiles from the perspective of a content consumer, or casual audience member. Thus, for the purposes of this study, we do not have access to deeper insight about the personas beyond what is accessible publicly through the web. To identify each subject for the remainder of this study I use short non-anonymised nicknames.
Limitations
The results are based upon a very small (albeit diverse) sample, and cannot be considered representative of content creators in general. I seek to describe a subset of behaviours within content creation social machines, but do not claim to be exhaustive.
I have no doubt that content creators have more online profiles which are not linked from their YouTube channels, however I was obviously not able to discover and study these.
Results
Profiles and personas
For ten content creators, 93 profiles were discovered. Of these, 23 were YouTube channels, 16 Twitter profiles, 13 Facebook, 9 Vimeo, 7 Tumblr, 6 personal websites, 5 Instagram and 4 Vine, 3 Google Plus, 2 Bandcamp and 2 DeviantArt and 1 each of Patreon, FormSpring, BlipTV, and Newgrounds. Table [6] shows how the profiles are distributed. As we can see, in the domain of creative content production identities are not site- or community-specific. Creators spread their activities across a number of networks in order to shape a more complete identity.
| Creator | # profiles | Mean profiles per site |
|---|---|---|
| Dane | 18 | 2.3 |
| Khyan | 13 | 1.9 |
| Bing | 13 | 1.3 |
| Lucas | 11 | 1.4 |
| Bown | 9 | 1.5 |
| Todd | 7 | 1.2 |
| Arin | 7 | 1.0 |
| Suzy | 6 | 1.2 |
| Ciaran | 5 | 1.3 |
| Chloe | 4 | 1.0 |
'Second channels' are common on YouTube. Creators who focus on one type of content (e.g. sketch comedy) publish this on their main channel as well as using their main channel identity for interactions on the site. On their second channel they publish content that they may consider to be of interest to only a part of their main audience, such as vlogs about their lives, out-takes from main channel content, or experimental pieces. Most content creators with second channels post explicit links to them on their main channel, and often publicise them within content metadata or as part of the content directly. In some cases, including those where the connection between two channels is explicit and obvious, the creators behave differently towards their audience through second channel content. This varies greatly depending on the type of content produced. In some cases, second channels may be perceived to be more reflective of the creator's 'true' personality, if they project themselves as more serious or honest, and publish more personal content like vlogs or behind-the-scenes footage. Whether or not this is accurate is impossible to know without intimate knowledge of the creators' offline life. The significance is that persona variations exist, and creators do not necessarily hide these alternative presentations of themselves from their audience.
Additionally, there are profiles which are not directly linked from the (self-identified) 'main' profile, or the links are treated as though the profile belongs to a different person. Figure 3 shows three screenshots of different YouTube channels showing different ways creators link out to other versions of themselves.
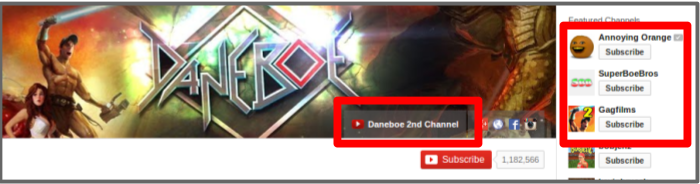


Creators also used their profiles to link to shared channels (where either multiple creators post content independently of each other, or creators collaborate to produce joint content, or a both), and channels of others with whom they regularly work.
Most of the platforms discovered which host profiles for the subjects of this study offer limited options for customisation, and the use of consistent branding between different systems was intermittent. This mostly took the form of identical or similarly styled display pictures, similarly phrased introductory paragraphs, and similarly styled content.
Some creators have profile sets across different platforms which are distinctly grouped into alternative personas. This was evident from the branding, content and connections between them.
Connections
How connections to other people were represented varied depending on the technical system. We can differentiate between mutual relationships between accounts (e.g. 'friend') and one-directional relationships (e.g. 'follower', 'subscriber'). Some systems offer both types of relationship, some one or the other. For YouTube channels, popularity ranged from over 3.5 million subscribers for Dane's character channel realannoyingorange to 118 for Bown's secondary bowntalks channel.
The importance of these connections varies depending on the system as well as on the attitude of the system user. Mutual connections may initially be presumed to indicate a closer relationship, but this is not always the case. Some systems allow users to accept all friend requests en masse, which they may do to please fans, resulting in a lot of essentially meaningless mutual connections. Instead, outbound one-directional connections come in far smaller numbers, and indicate the content creator is particularly interested in the outputs of the other creators they choose to follow. It appears normal for content creators to follow other creators with whom they have collaborated.
Although their use is to some degree shaped by community norms, such connections are strongly influenced by the architecture of the particular website. However, most of the websites examined allow enough control over the textual content of a profile that profile owners can manually create links to other documents on the web, potentially circumventing the site's built-in connection mechanisms. Creators may also be able to adapt the content publishing interfaces to add additional connections (e.g. adding links to Twitter and Facebook accounts in the description of a YouTube video), and often do. These connections necessitate extra effort on the part of the content creator, and tell us more about their relationships with other online accounts. Figure 4 shows different types of connections between profiles and personas for one content creator.

Summary
Content creators at all levels of activity do not have straightforward relationships with the systems they use for publishing and publicising their content. Through manually examining profiles, it is possible to identify personas, and connections between creators, and learn about the likely explanations behind them. Currently there is no way to formalise these deductions, so in the next section I propose a small taxonomy for describing the experiences of individual participants in social machines.
Taxonomy
Based on the findings previously described, I propose four closely linked but distinct concepts that are useful in a granular discussion of identities of social machine participants: roles, attribution, accountability and traceability. I will explain each in the context of creative media production social machines, and show how they can be used as dimensions to assess the nature of individual identity in a social machine.
| Dimension | Description | Degree | ||
|---|---|---|---|---|
| 0 | 0.5 | 1 | ||
| Roles | the ease with which participants can change the role they play in a system | one role, everyone equal | multiple roles, participants play one | multiple roles, participants move between them |
| Attribution | whether or not crediting participant contributions is important | unimportant | sometimes important | very important |
| Accountability | whether the provenance of the inputs make a difference. In a Social Machine where this is critical, regulating identities to ensure trustworthy data would make sense | unimportant | sometimes important | very important |
| Traceability | the transparency or discoverability of connections between different profiles and personas | required, or mostly useful | optional, may be useful or harmful | not required, or likely harmful |
Roles
A creative media production social machine contains at least consumers, commentators, curators, and creators [Luther2007a]. These roles are interchangeable, and content creators may wish to adopt different personas according to the role they are playing. Plus, content creators are often multi-talented and they may wish to put on a different face according to the different types of content they publish. How easily this is accomplished - according to the social expectations and technical affordances of systems that are part of a social machine - can impact the behaviour of participants.
Attribution
In content creation communities, contributions to media output are directly connected to building reputation, so content creators generally desire to have their name attached to work they produce. If the publication system does not allow this directly, as is often the case for sites that host collaborative works (a video published on one YouTube channel may contain contributions from several creators, each with their own channels but formally linked with only the uploader), then creators adapt the system as best they can, eg. the uploader may list links to the channels of all contributors in the video description [Luther2010]. Even when a content host site provides automatic linking to other user profiles – common in remixing communities – this isn't necessarily enough. [Monroy-Hernandez2011] finds that human-given credit means more, and so free-text fields for content metadata are often used anyway.
Accountability
In many of the commonly-discussed social machines, like Wikipedia, Galaxy Zoo, Ushahidi, and the theoretical crime data social machine in [ByrneEvans2013], accurate data is critical to the usefulness of the output of the system(s). Thus, accountability through identity is important. It is reasonable then to want to regulate participants somehow. But this is not universally applicable.
The production of creative content is a domain that exemplifies the need for taking a more flexible approach to identity understanding and management. On the one hand, creators wish to be accurately credited for their work and plagiarism may even result in a financial or reputational loss. On the other hand, creators may appear under multiple guises, engage in diverse behaviours and make contradictory statements about their participation in a creative work, all in the name of entertainment. Creators may also engage in some activities under an alternative identity in order to avoid any effect on the reputation of their main persona. These are valid uses of the anonymity provided by online spaces – a core feature of the World Wide Web. These activities won't necessarily even result in diminished trust. A content consumer may fully enjoy a series of vlogs, unaware that the vlogger is a character and the life events portrayed are entirely fictional, and be none the worse off for it.
Traceability
We consider traceability in terms of the settings in which an individual might interact with others. A person participating in a creative media production social machine may exist behind a different persona when participating in a scientific discovery social machine, and yet another in a health and well-being social machine. The discovery that other participants in the health and well-being social machine are aware of their alternate persona in the creative media production social machine may cause them to amend one or both of their personas. If the risk of their multiple identities being 'discovered' is high they may adjust their behaviour accordingly, whether this is ceasing all attempts at 'deception', or taking steps to decrease the overlap of the communities of which they are a part.
Well known content creators often appear at offline events to meet their fans. Those who star in popular live-action video content are recognised in the street. They are interviewed by journalists and contracted to produce viral adverts by marketing companies. Only with careful control of their online persona can they successfully engage in offline interactions like this. A content creator who believably portrays an undesirable character across multiple platforms online may not be considered a candidate for a job in broadcast media thanks to the blurred lines between reality and fiction, online and offline.
In 2017, video game commentator Felix Kjellberg (PewDiePie) lost a lucrative contract with Disney and Google for using racist language in his voiceoversp. In 2014 vlogger Alex Day was widely renounced by his online community (as well as his record label) because of offline allegations of sexual assult and abusive relationships with fansa. Different worlds interact; contexts collapse, and the repercussions are felt through them all.
An example in which the traceability of personas was crucial is the DARPA Network Challenge [Tang2011], for which participants needed to provide their 'real life' identities to win the cash prizes. Even if they had operated under pseudonyms during the competition, in order to validate their claims they needed to make known these personas and consolidate them with an identity that would allow them to receive the prize money.
Since a YouTube profile is not assumed to be representative of a single complete individual, profile owners must find other ways to establish and moderate the relationships between their profiles. How they do this will depend on the roles they play, and their motivations in taking part. Knowledge of others present - audience and colleagues - in the online and offline spaces in which someone spends time may influence how they establish their personas in these spaces. An evolution of these spaces or a change in the individual's circumstances over time may cause them to revise their personas.
Applying the taxonomy
We can apply these concepts to social machines in order to understand the significance of individuals' identities within them. We use some well known social machines as examples for each dimension, in Table 8.
| Dimension | Examples | ||
|---|---|---|---|
| 0 | 0.5 | 1 | |
| Roles | ReCAPTCHA | The Obama campaign | Creative media production |
| Attribution | ReCAPTCHA | Wikipedia | Creative media production |
| Accountability | GalaxyZoo | Creative media production | A crime reporting social machine |
| Traceability | DARPA network challenge | Creative media production | Mental health support forum |
| Refer to Table 7 for descriptions of each dimension, and what the numbers mean for each dimension. | |||
Discussion
I have demonstrated through an empirical study that participants in social machines often have complex relationships with their own self-representation, and with their connections to others in a system. Individuals may have one-to-many or many-to-one relationships with online personas, for a number of different reasons, and with different levels of transparency. This section includes a taxonomy of four dimensions: roles, attribution, accountability and traceability. We can use these to better understand individuals in a social machine in relation to the whole, despite this complexity.
Contributions to the 5Cs
The role(s) taken on by an individual are affected by the extent to which an one is able to create and discard identities. Whether participants can be attributed or held accountable for their contributions, and the extent to which one identity can be traced to another, are affected by whether identities are persistent, and whether anonymous contributions are accepted. These are all aspects of the control someone has over their online self-presentation.
Roles arise through, and may be enforced by, either the technical affordances of a system, or the social expectations of a community (or both). The role(s) an individual chooses to take on may also be affected by their personal motivations, desires or needs. Thus understanding roles requires us to account for the context in which a system is being used.
Through Attribution and traceability we discover the connectivity of a system. Participants may see each others' contributions, and may build reputation accordingly and present a particular impression to their audience. This reputation and impression can translate to other technically disconnected systems if identities are transparently linked.
The degree to which connections between identities are traceable affects the spread of information about an individual. Intended or unwitting links between personas contribute towards an automatically generated or inferred aggregate profile. This spread may feed into unknown systems on and offline, and have unforseen consequences. I label this the cascade.
Deliberate traceability may be created between profiles on different systems through consistent visual branding, as well as actual hyperlinks placed in profiles and annotated. This is only possible to the extent that systems permit participants to customise their profiles.
The many dimensions of lying online
In the previous study we see some of the creative ways in which individuals work around constraints of even flexible profiles in order to meet their expressive needs. We learned that misrepresenting one's real-life identity is not necessarily in conflict with the functioning of the system, and may even be a culturally important aspect of participation.
I expand on these observations with a survey of social media users who reveal the ways in which they bend the truth in their online profiles, and why, and how they feel about others doing so. Portraying matters as other than they truly are is an important part of everyday human communication. The survey enquires into ways in which people fabricate, omit or alter the truth online. Many reasons are found, including creative expression, hiding sensitive information, role-playing, and avoiding harassment or discrimination. The results may suggest lying is often used for benign purposes, and conclude that indeed its use may be essential to maintaining a humane online society.
The results are a set of categories which characterise the spectrum of lying and deception practices routinely used online: system, authenticity, audience, safety, play, convenience.
This section was adapted from work originally published as Self Curation, Social Partitioning, Escaping from Prejudice and Harassment: the Many Dimensions of Lying Online at ACM WebSci 2015 with Max van Kleek, Dave Murray Rust, Daniel Smith and Nigel Shadbolt. I participated equally in the design of the survey, participant recruitment, and coding and analysis of the results.
Introduction
People avoid telling the full, open, and honest truth
in many situations, whether it involves simply the omission or falsification of information, to more substantial forms of deception and lying. Such behaviours have been shown to amount to, by some accounts, nearly a third of offline interpersonal communications [depaulo1996lying,bok2011lying].
This study is aimed at prolific internet users, who spend a substantial part of their daily lives in social encounters online, therefore likely to engage in the widest variety of such behaviours. We are particularly interested in how such practices arise or are used differently across contexts, situations, and spaces. We are interested in the intent behind the deception, but we do not examine the moral or ethical dimensions of such practices, as these can be highly subjective and grounded in particular personal philosophies.
As described in the following sections, our analysis found that while there are a wide range of reasons people use deception online, few reasons for doing so are self-described as malicious (or comprised of dark lies
); in fact, a majority of the reasons involve impression management, conflict avoidance, and in order to fit in to groups.
Context and research questions
As individuals increasingly manage multiple social contexts of growing complexity in their daily lives, techniques are required for navigating the interlocking and often antagonistic demands placed on them. Examination of deceptive practices has shown that they often serve as coping strategies for managing and mitigating these complex social situations. Examples of such reasons include protecting one or another's reputation or identity, to preserve particular relationships or ties, avoiding confrontation, showing solidarity with another, and covering up accidental transgressions, among others [hancock2007digital, Burgoon:2003:TDM:820748.821362] Various background concepts relevant to interpersonal deceptive practices are discussed in chapter 2. Of particular interest are butler lies, to ease social interactions, and subconscious adjustments to self-presentation to remain authentic in context.
As the prevalence of computationally mediated socialisation increases, so does the need to understand the role and use of lying and deception in online interaction, and to uncover the kinds of social tensions and attendant complexities that arise from the new social affordances that the Web provides [hancock2004deception]. People now conduct their interactions and curate their identities across a large number of online spaces whilst attempting to balance their privacy, reputation and roles throughout. Deception is a tool used to cope with this complexity, and a lens through which their difficulties and needs can be observed [hancock2007digital, Burgoon:2003:TDM:820748.821362]. We attempt to characterise peoples' online behaviour through the simple question: Why and how do people lie on social media?
Study Design
Method
We took a several-step approach to designing the survey questions. First, we looked for precedent in previous surveys (e.g., the Questionnaire on Academic Excuses for student lying behaviour [roig2005lying], elicitation method for daily lying studies [depaulo1996lying]).
Second, we iterated on the phrasing of the questions by consulting other colleagues as experts in the process to shape the specific foci and wordings. We initially considered several methods besides survey, including semi-structured interviews, and artefact examinations, but fell back to a web-based survey to be the most appropriate for getting a wide sample from our target population. In order to characterise the broad class of behaviours we wanted to examine, we first showed a list of candidate terms including terms such as deceptions, lies, falsifications, omissions and untruths to several experts, alongside a small but diverse list of example behaviours we wished to seek. Our colleagues, comprising two Web Science doctoral students and three postdoctoral researchers, gave us feedback about which term(s) they considered most appropriate, and then discussed the range of behaviours we were seeking to elicit. The outcome of this process was to break out three distinct questions: one pertaining to the use of untruths, one pertaining to the use of pseudonyms, and finally to the use of fictional personas, which are identities for characters that were entirely fabricated.
The survey was delivered via the web, and comprised 12 sets of questions including one set of demographic questions, and 8 open-answer free responses. In this analysis, we focus on the subset of the questionnaire delineated in table 9.
Analysis of free-response questions was done using a grounded theory [strauss1990basics] approach; themes were identified across responses through a process starting with open coding process by each of three researchers separately, followed by a discussion process where themes were refined and combined. Multiple themes were permitted per entry. Once consensus was achieved on themes, all responses for a given question were re-coded against the final set.
| No. | Question | Answer type |
|---|---|---|
| Q4a | Have you ever told lies/untruthsonline? Why? | free text |
| Q4b | How often do you tell lies/untruthson social media? | 5-level Likert |
| Q4c | How often do you think your friends lie on social media compared to you? | 5-level Likert |
| Q5a | Do you use any pseudonyms online? Why? | free text |
| Q5b | Have you created any fictional personas? Why? | free text |
Participant recruitment
The survey was published online, with no restrictions on participation. General recruitment was carried out by handing out flyers with the URL, and the researchers' social media presences (primarily Facebook and Twitter). This was augmented by enlisting two people with popular twitter accounts (@TheTomSka, 191k followers, and @DameWendyDBE, 4k followers) to promote the survey.
In order to ensure a good selection of passionate internet users — people who live a lot of their life on the Web, and care about their online presence — additional recruitment was carried out in person at two events in London: ComicCon and the WebWeWant Festival during summer 2015.
Limitations
Among the limitations of the study, the self-report of lying behaviours may be different from actual practices for several reasons; retrospective bias effects may cause consistent under-reporting (e.g. I think I am a mostly honest person, therefore I really must not lie that much
). A second reason that self-report is challenging here is that, due to the degree to which lying practices may be ingrained, there may be classes of behaviours that people may not consider, realise or think of as lying or deception at all. Indeed, a major class of butler lies were not even perceived as lies by participants of a prior study [hancock2009butler]. In order to mitigate this effect, we iterated on the wording of the survey questions to try to elicit as wide a variety of relevant behaviours as possible, as described in the method. Second, as with all surveys, selection-bias effects may have affected the results; in particular, those that volunteered (or, indeed, took any notice to begin with), were perhaps more likely than not to have a pre-existing interest in these topics.
Another limitation of this study is that it is reflective of only one specific demographic that we targeted; young, Western, social media enthusiasts comprising YouTubers and other 'web nerds', as these individuals have been shown to have complex, entangled online social lives [boyd2014s, livingstone2008taking, lenhart2008teens, lenhart2010social, madden2013teens]. As such, the kinds of concerns and experiences people reported may not be representative of other Web demographics; for example, some demographics may be less likely to maintain separate fictional personae online, or have any need to keep separate their social media fanbases. However, studies of specific online groups, such as gamers on MMORPGs [yee2006demographics] have demonstrated that demographics were considerably more diverse than previously suggested, particularly in specialised online communities [chan2011virtual].
Finally, this study is an exploration of the kinds of untruthful practices carried out rather than an attempt to rigorously determine how often they are used. As such, we have not leaned heavily on any quantitative analysis — frequency counts have been used as an organising principle rather than a means of comparison or a fundamental part of our claims.
Results
Out of the 500 survey responses, 39% (198) provided a gender; 50.2% responded female, 49.8% male, and 1% transgender. With respect to age, 59% responded, 91% were between 18 and 25, 7% 26-35, and 2% 36+. The age distribution skew was reflective of, and likely due primarily to, the predominantly young audiences at the two festivals.
Nearly all respondents were very active social media users, although use of particular platforms varied significantly. Figure 5 shows the self-reported Likert scores per platform for six social media platforms. The popularity of YouTube and Twitter for respondents was likely influenced by the method of recruitment (via Twitter), and the fact that one of the popular Twitter users who disseminated news of the survey is a popular YouTuber. The other platforms, meanwhile, were more divided, with Tumblr being the most divided between highly active (125, 27%) and those that never used it (144, 32%). Vine was used the least overall with (422, 91%) reporting having either never or rarely used it.
Self-reported frequency of deception/lying
In terms of frequency of lying, 77% of participants (N=387) responded to Q4b, How often do you lie on social media? the distribution of answers is is displayed in figure 6-a]. The median response was 2, with a majority (N=330, 85%) of responses answering either a 1 or 2.
Question 4c asked How often do you think your friends lie on social media compared to you?, and 77% (N=386) again responded overall (figure 6-b]). The median value was 3, with (N=87, 22%) responding with a value that their friends lie less than they do (e.g. 1 or 2), while (N=119, 30%) responded that their friends lie more (e.g. 4 or 5).
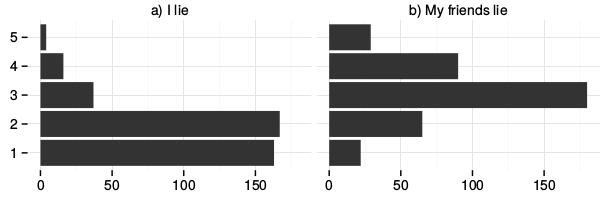
Responses to Q4b and Q4c on Likert scales
b) How often do you tell lies or untruths on social media? (1=Never to 5=Often)
c) How often do you think your friends lie on social media compared to you? (1=Vastly less to 5=Vastly more)This figure is missing?
Reasons for Deception
A total of N=134 responses were received for Q4, which asked people to explain whether they remembered telling lies (or untruths
) online and to explain the circumstances. Out of the total respondents a quarter (N=34, 25%) answered that they had or did not lie or use any form of deception online. The rest of the respondents admitted to performing some form of deception regularly.
Thematic coding of the remainder of the responses revealed 12 themes, listed in Figure 7, including an extra for yes, a category standing for responses admitting participating in deception with no explanation, and no for responses that denied using deception on social media.
The most prominent theme was playup (N=35), which corresponded to the rationale of wanting to be more appealing, interesting or attractive to others. There were several subtypes of this activity, starting with simply falsifying personal attributes (height, weight, age) towards what they perceived would make them more attractive, to exaggerating details of stories, to making things seem relatable
. Four respondents mentioned aspects relating to making one's self seem popular or important by filling their social calendar to appear busy, while two discussed fabricating stories, such as of having met celebrities. Contexts ranged from online dating to social interaction with strangers.
Less common, although present were responses about fabricating or creating fictional events and situations (N=3), while two respondents described appropriating other people's content, including funny tweets
and status posts, as if they had been their own.
Far less common (N=9, 7%) was the opposite reason, in which participants reported deliberately distorting or omitting information in order to not attract attention or in many cases to prevent disclosure of illness or situation to protect their reputation. This theme, coded as playdown, included the following responses:
Lied about my mental health countless times, denied depression and suicidal thoughts. (354)
I very selectively curate my online personae, particularly on Facebook, where I am careful to hide my mental illness, my frustrations, and my negative emotions. (461)
I tend to lie about how sick I am so people don't worry/employers don't get anxious. (49)
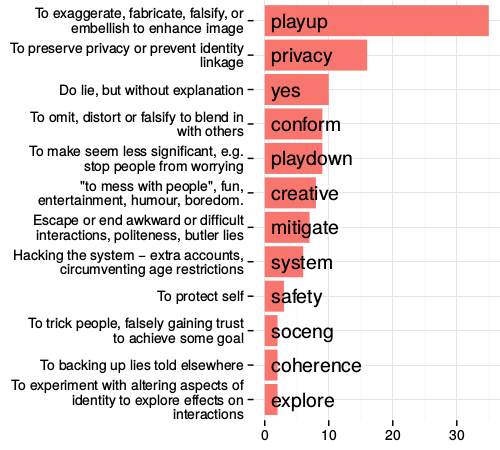
untruthson social media, given fictitious info, omitted or distorted the truth online?
The second most prominent theme after playup was privacy, a theme used to encompass a variety of privacy related concerns. Respondents reported explicitly withholding information often, and, where information was required, providing false values about themselves. The attributes most often mentioned were age (N=17), real name (N=13), physical location (N=6), gender (N=3) and birth date (N=2) to web sites that they did not trust. Four mentioned that this was in order to prevent identity linkage to their real-world identities, e.g.:
On fetish sites, I will lie about my birthday (displacing my age by a few months to a year in the process) and my hometown, making my identity there harder to connect to my real identity. (461)
Others said that they adopted the strategy of falsifying attributes when social networks asked for information that they felt to be unnecessary, for example:
Whenever a social media asks me to provide personal details which are not directly necessary for them to deliver the service (e.g. Facebook asking for my workplace), I constantly feed them wrong information. First and foremost to stop them asking me for such information while at the same time keeping my personal data private. (500)
A different reason given for falsified attributes was coded as conform, when falsification was done in order to fit in, in particular to avoid harassment and discrimination. Such behaviour including avoiding potential confrontation surrounding personal beliefs (pertaining to religion or politics), or to personal attributes including gender, age, race or sexual orientation. One participant described her choice of declaring herself as male improved her position in debates online which were often predicated with ad feminam attacks on her gender:
if I pretend to be a man my sayings won't be regarded through the bias of my gender, while if I say opinions (completely disconnected from gender issues) as a woman, it will probably be the 1st thing my opponents will use in a debate. (301)
A smaller category (N=6) involve tricking the system in some way (system), predominantly falsification of age in order to circumvent controls on age-restricted websites.
Another set of responses (N=6) corresponded to deception or lies told for fun, humour, or just messing about
. The tag creative was used for this group, which included examples such as pretending to have a twin, pretending to have met someone famous, or permuting another person's words.
Lies used to diffuse, or bring an end to, unwanted social situations we called mitigate. This class (N=7) was a superset of butler lies; while butler lies serve primarily to terminate and divert unwanted social interactions, the lies in this category included those which were told to be polite, such as agreeing with a person to avoid an argument. Meanwhile, safety (N=3) corresponded to the responses describing omission or falsification to avoid compromising one's physical safety, or from potential litigation for potentially illegal activities.
Some users described the use of deception in order to deceive, trick or manipulate situations to the individual's advantage; such reasons were coded soceng (N=2) because it reflected the common notion of social engineering
.
These responses described falsification of academic credentials for jobs and posing as another person online and attempting to attract her partner's attentions as this fake identity in order to test her partner's loyalty.
Finally, explore, and coherence each had two responses. The first, explore, pertained to responses that discussed experimenting with aspects of their identity, in particular to test the reactions of others
. Meanwhile, coherence was the act of lying in order to maintain consistency with other lies told elsewhere to prevent lies from being discovered.
Pseudonyms
| Code | Description |
|---|---|
| bespoke | Several online identities kept separate. |
| character | Role-playing an obviously fictional character. |
| conform | Conform to community norms, fit in with others. |
| creative | For entertainment or creative purposes. |
| discoverability | Use of a pseudonym to connect identities or be discoverable. |
| discrimination | Avoid being judged unfairly. |
| disnomia | Dislike real name. |
| experiment | Role-playing different real-world identities to experience the way they are treated, and/or trying to get someone else's viewpoints. |
| expression | Saying things without fear or repercussions. |
| habit | Force of habit. |
| hide | Hiding activities from everyone. |
| identity | Online identity more closely matching true self. |
| intimate | Posting intimate thoughts and feelings. |
| no | No, with no reason given. |
| nothide | Use of a pseudonym, but not trying to hide one's identity. |
| plus | Mentioned the Google+ real namespolicy. |
| privacy | General feeling of not wanting to reveal stuff. |
| reuse | Used a nickname or variation of offline names. |
| safety | Protection from other people. |
| separation | Separate concerns (professional, family, between friends). |
| sex | Anything about sex. |
| soceng | Tricking people or gaming the system e.g. falsely gaining trust, fake qualifications, circumventing age restrictions, using sockpuppets, and spam control. |
| spy | The system is spying on me, merging my accounts, and sharing data. |
| yes | Yes, with no reason given. |
| - | Theme unclear from answer. |
| Question 5a is Do you use pseudonyms on any social media platforms? Why do you do this? Do you try to hide your real name/identity? and 5b is Have you created any fictional personas (e.g. characters, alter-egos) to use on social media? | |
A total of N=286 responses were received for Q5a, which asked for information about whether participants had used pseudonyms, and why. A group (N=82, 27%) claimed not to use pseudonyms online, and a further group (N=5, 2%) gave answers which were unclear. This left 70% of respondents claiming to have used an online pseudonym.
The most common reason for pseudonym use was tagged as separation (N=63, 22%). This covers several different lines of division. The three most prevalent reasons were i) separating online and offline lives; ii) separating personal and professional identities; and iii) maintaining distinction between groups of friends or family:
... It was mainly done to slightly separate my identity from reality and the internet. (266)
... I also do not want future employers and such to be able to find all of my social media straight away and making judgements based on it. (79)
... I used to have a nerdy YouTube channel which I did not want my peers finding out about, so almost all of my online activity connected to that was under a different (screen) name. (150)
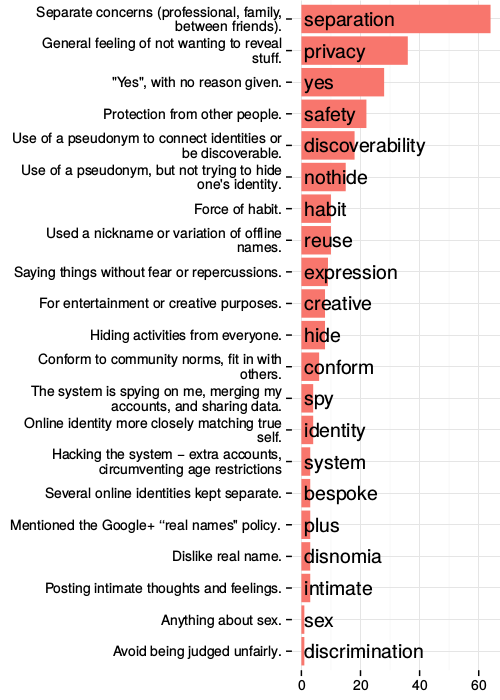
Related to separation, several people used pseudonyms to hide (N=8) their activities online. This is distinct as it covers activities that they would like no-one to know about, rather than seeking to separate different identities. Most commonly, this had to do with pornography:
Yes, especially when using pornographic sites such as Chaturbate. (183)
However, there were also examples of more general hiding:
I have to do things that people don't need to know about but I don't hide my real persona. (398)
The next most common reasons were privacy and safety; while these codes are related, there are some distinctions in the meanings we found. safety (N=22) related to a fear of repercussions spilling out of that particular online world. Some of these threats were specific ideas of violence:
As a person on the internet with (rather unpopular) opinions I find myself constantly subjected to pretty severe harassment such as very graphic rape and death threats, so I feel it would be safer to reveal little to no identifying information on certain platforms. (168)
Many people were concerned about the idea of being stalked, of what might happen if people could find them 'in real life', while others had a general sense that one should be safe or careful online:
Yes, I do, because I am concerned that people might stalk me if they know my real name. (184)
... tends to involve a lot of total strangers, so I feel I need to be more careful. (169)
This is distinct from the responses concerned with a more general notion of privacy (N=36). This code was used for responses which simply mentioned privacy, or a desire for one's data not to be shared. This ranged from a passive sense of not wanting to share more than necessary to an active, explicit desire to maintain privacy:
... I just don't feel the need to have that info on there at the moment... (151)
Some users were also change names in order to reduce the ability of systems to spy on them, or share their data unnecessarily (N=4).
Not all uses of pseudonyms related to hiding or privacy. A significant number of people (nothide, N=15) explicitly stated that they were not using a pseudonym in an attempt to hide, while several carried on using pseudonyms out of habit (N=10).
I use pseudonyms because they're fun, I don't use them to hide my identity, I'm not batman. (383)
A slightly larger number (N=18) used the pseudonyms to aid in their discoverability, by having a common name across several platforms, or to conform to the norms of the community (N=6).
Similarly, several people (N=10) reused real-world identities, often in order to allow people they know offline to find them. There is often an exclusive component to these responses, that only the desired set of people will be able to find them:
Normally just a username which is based on my real name because if you know me then you will know it is me otherwise you would not (223)
People also used pseudonyms to support creative activities, or simply for amusement (N=8). They also allowed the expression of parts of their personality without fear of repercussions (N=9), sharing of intimate content (N=3), and a presentation closer to their internal identity:
I really identify as a guy, so I go by a male name. Nobody IRL knows about that though. I do this cause I just want to be... Who I really am inside? Cheesy, but true. (44)
Some people (N=3) had a dislike of their civil name, and simply wanted a change, or had a desire to create bespoke identities for certain activities (N=3).
Finally, a few people used pseudoynms in order to have multiple accounts to manipulate the sociotechnological system (N=3) — avoiding copyright issues, or tracking who sends spam mails.
Three people explicitly mentioned Google+'s insistence on real names or merging accounts, one person created a pseudonym to escape discrimination, and one in the pursuit of sex, and .
Personas
A total of N=267 responses were received for Q5b, in which participants were asked if and why they had created any fictional personas for use on social media. 65% reported that they do not or never have; 5% responded in an unclear manner or described pseudonyms (just changing their name) rather than personas. Of the remaining third, the most common reason was for creative purposes (N=21), including to entertain themselves or others. Related to this are those who explicitly state they're role-playing a fictional character (N=11) and those creating bespoke identities (N=1).
I just role-play characters I like to escape from my everyday hell hole. (44)
I use another persona to have fun telling fictional stories. (256)
I have a blog that I update in the voice of a character but thats for my own personal use as it's helping me to write a book (443)
I have and i did it because i created a fictional character and i wanted to give the illusion that the character was real (449)
I did so to make fun of some naive friends on a facebook group. (482)

The next most common response (N=10) was to experiment, including testing the reactions of others to different ages, genders or political views, or for self-exploration.
I use to when I was younger on tchat to see How people talk to different kind of people (male, female, younger, older etc...) (112)
yes. many... i do this to role play different personalities online and sometimes learn more about my actual persona by doing so. i like the act. (303)
...I have created two alter-egos. One was a short-lived novelty account that posted in the voice of a fictional character, while the other is a member of a hate group whom I used as a kind of psychological experiment in empathy — by performing as a member of that group, I came to a fuller understanding of what compels their bigotry. (461)
N=8 responses were tagged with separation, where respondents created personas to separate work and social lives or posting of different content types.
Yes, to comment on Youtube, because I don't want Google+ on my regular upload account. (381)
i've got accounts to post on when i feel annoyed so that friends/family dont see and it doesnt affect their impression of me (444)
Yes, I have 2 different twitter accounts that I use, one for general Fan base use which I am an overactive mad sloth and one which is for school people to think is my only one (492)
Some users took on pseudonyms for privacy (N=3) or to aid their self expression (N=3) finding it gave them the power to give voice to parts of their personality:
Yes, it helps me be more confident and say things to people that I would otherwise be unable to say. (371)
Social engineering was also a motivation (soceng, N=3), typically pretending to be someone new to gain trust or find out people's private opinions:
I once created a fake persona to ingratiate myself with an online community and see what they were saying about me in private. (473)
Finally there was one respondent with each of the following motivations: resistance to the system spying on them, or explicitly fighting the Google+ real names policy (plus); force of habit; presenting an identity closer to their 'true self'; and for sex.
Themes
Examining themes common to all of the questions we analysed, we consolidated them into five groups, which are discussed here.
Audience
Several of the themes cam be considered reflections of offline social practices. Impression management behaviours such as playup, conform and mitigate commonly occur in day-to-day life. The online performances aimed at impressing friends and attempting to diffuse awkward social encounters seemed largely analogous with their face-to-face equivalents.
Similarly, a number of participants attempted to playdown or not disclose problems they were having — they described their motivations as not wanting to worry others, or not wanting employers to find out. These participants are essentially using lying to manage how others perceive them, effectively giving them more control over their illnesses, rather than being forced to disclose them, and having to deal with potential consequences of that disclosure. This particular use goes beyond the butler lies phenomenon discussed previously, and instead enables control of psychological projection and public perception of self online.
Pseudonyms and personas, meanwhile, were commonly used as mechanisms for preventing context collapse [hogan2010presentation, boyd2002faceted, Marwick2010], maintaining a separation of concerns between different facets of respondent's lives. Identity was partitioned based on both the content posted and the intended audience. This included having separate Twitter accounts for personal vs. professional posts; 'secret' accounts used to interact with fandom communities away from the judgemental eyes of peers; and pseudonymous Tumblrs which allow the solicitation of advice from strangers regarding their non-parent-friendly intimate secrets.
While it is apparent that many of the deceptions discussed are neither new nor malicious, and complement or mirror pre-Web forms of social mediation, some were self-reported to be less innocent. Responses in the soceng category included creating fake accounts to stalk an ex-partner or to test the faithfulness of a current one; gaining trust to see what people were saying about them behind their backs; and manipulating social situations for personal advantage.
Another reason to construct a persona or mislead others about certain aspects of themselves was to conform or fit into a particular community. Online communities quickly develop cultural norms and expectations and participants tend to engage most successfully if they follow these.
Authenticity
Some respondents reported being able to project their true selves online in a way that they cannot elsewhere. This ranged from simply using a name they felt more comfortable with, to being able to disclose attributes, ask for intimate advice, or engage in activities that they did not feel they are able to do in their offline lives. This is contrary to what systems such as Facebook claim: that 'authentic' users tell the whole and only truth about themselves [guardian]. This shortsightedness misses that some individuals are forced to play roles in their 'real lives' to meet others' or societal expectations, but which are discordant from how they really wish to live.
Convenience
Consistent pseudonyms were reported as useful for allowing others to track individuals across platforms (discoverability, coherence), or link certain aspects of their persona together whilst excluding others, without requiring the sharing of any personal details. This would perhaps not be required if disparate systems cooperated with one another to permit some kind of data sharing or account linking. This connects to the concept of traceability from the earlier Constructing Online Identity study.
Others reported they maintained pseudonyms or personas out of habit, something which they presumably would not continue do if, despite what certain systems want users to do, behaving closer to their 'true' identity dramatically improved their interactions with the system.
Play
Lies in the form of impersonations, parodies, role-playing, or storytelling were used creatively to entertain others and alleviate boredom — just as joking around in person would do. The behaviours reported are extensions of ways in which people construct the multiple facets of their identity offline. This is consistent with findings reported by boyd following ten years of ethnographic studies of social media use by teenagers [boyd2014s], that the primary attraction of social media to young people is the ability to claim a social space of their own, in which they can 'hang out' when restricted from being physically co-located with their peers. boyd argues that privacy norms have not changed as technology executives like Eric Schmidt and Mark Zuckerberg would have us believe, but rather that young people are continuously evolving new ways to maintain much-desired control over social situations [boyd2014s, guardian].
Some of the reported behaviours serve to highlight differences between online and offline practices. While role-playing is used in the real world in order to help people work through difficult or novel situations, the malleability of identity on social networks enables participants a greater control over how they present. This allowed several people to put themselves in the shoes of others, to experience the treatment given to women, or the feeling of being part of a hate group.
Safety
Most people are told from a young age not to talk to strangers in the street, the even more uncertain nature of the audience of online interactions seem to make many of our respondents innately wary. Altering or omitting personal details was considered 'the done thing' by many, who either feared for their physical safety or just wanted to avoid nasty comments. Some had a sense that they would be stalked by strangers if they revealed their location, regardless of whether or not they considered their online activities provocative.
A small number of respondents said they could alter their identity to avoid discrimination, allowing an ease of engagement which was otherwise not available. This illustrates empowering potential of the Web, where the ability to control information about oneself can be a positive force for good.
System
There is distinction between respondents concerned about maintaining their privacy from other people, and those concerned about privacy from the platforms they use. From those who felt that systems simply did not need to know all their details, or were suspicious of advertising tactics, to those who were specifically concerned about the context collapse that might result from social networks which merge or cross-post to each other (e.g. Google+ and YouTube).
Another observation from our study relates to how platform restrictions become barriers to the kinds of activities we described. Platforms can limit control over identity accidentally or deliberately, through policy or technically.
In particular, it is clear that several of the deception strategies described were deployed in order to preserve safety, privacy, or separation of identities in the face of platforms that were designed to thwart such separation and/or anonymous use.
Common examples include providing false attributes to platforms that required personal info it had no business asking for
and creating separate identities where platforms provided no means of opting out of advertising or tracking.
Perhaps the most irksome to the participants of our study was the consolidation of YouTube and Google+ identity namespaces with the introduction of policies requiring the use of real names.
Opposition to this policy gathered over 240,000 signatures in a petition in 2013 when the change was made [noplus], indicating the widespread desire to maintain separate, controllable identities.
Examples of careful and deliberate control over public profile information on YouTube are documented earlier in this chapter [guy2014], showing that strategies for persona management continue despite attempts by Google to reduce the fluidity of identities of their users.
Discussion
In summary, this study found that people self-reported many routine kinds of lying, deception and omission strategies, reflecting a variety of needs and coping strategies for sustaining healthy, safe, and fun social interactions online. Only a small proportion of responses found deliberate attempts to socially manipulate others, while the vast majority corresponded to instances of trying to make oneself look good, maintaining separation among one's personal, professional and other social roles, fit in with others, avoid harassment, avoid causing others' worry, and to protect themselves from potentially harmful violations of privacy.
Despite not asking about platforms in Q4 or Q5, many participants mentioned adopting behaviours for specific platforms, for example, to separate their 'intimate' content on Tumblr, or to mitigate potential privacy concerns with trolls on Reddit or YouTube.
The fact that users must take active steps to circumvent the default behaviour of systems to maintain their online presence(s) suggests that current social media platforms have some way to go to provide a service that sufficiently affords the complex self-representation needs of users. The variety of benign and positive reasons users had for creating untruths indicates that these representations should be supported in order to maintain vibrant online spaces.
Developers of emerging systems can consider how they expect their users to engage, and then reflect on the types of reasons individuals fabricate or modify their personal information online: for playful reasons, for their own safety, for convenience relating to how they currently use or have used other systems in the past, to be authentic to their true selves, and to mitigate against intrusive systems — and then decide which of these they want to facilitate, rather than work against, to provide a better experience for their users.
In the next study, we design some systems explicitly for enhancing 'deceptive' possibilities in online interactions and explore how people respond to these.
Contribution to the 5Cs
In considerations of audience, we see peoples' offline social interactions reflect into their online spaces; we witness behaviours like diffusing awkward situations and managing context collapse. On the one hand, people claim and explore malleable fluid identities thanks to the opportunities provided by disembodiment (per play). On the other, they seek to prevent consequences of online interactions overflowing dangerously into the offline world (per safety). These scenarios each imply control over their online presence(s), in different ways and for different reasons.
Reflecting on one's audience also highlights the connectivity of networked publics. Those who knowingly manipulate others online, or unconsciously engage in impression management, consider to some extend by whom they are seen.
Constructing one's online presence according to community norms and expectations, as we see in audience, also suggests the customisability of online profiles. So too do the actions categorised for this study as play and authenticity.
Managing context collapse or dealing with the seams between different facets of life also contributes to our understanding of the cascade. People are not infrequently thrown off by data filtering through and across systems in unexpected ways. This is particularly evident from the mitigating behaviours described in system.
Finally, we have several contributions to our concept of context from this study. Fitting in with a community or particular audience forms part of the digital context in which one interacts. External, cultural or societal context are reflected in peoples' concerns about safety and authenticity. Personal, immediate practical context comes through convenience. So too does the technical context of a system itself and its constraints; this is also seen with peoples' anti-system defense mechanisms.
Computationally-mediated pro-social deception
Building on the previous survey, which broadly classified people's motivations for engaging in deceptive behaviour in their social media profiles, we conducted an in-depth interview study to better understand individuals' thoughts about deceptive behaviour in digital social systems. We particularly focus on the themes safety, system, and audience as we draw out how deception facilitates social behaviours in networked publics.
This time rather than asking about participants' current habits with real systems, we designed vignettes of five fictional but feasible systems which deliberately exaggerate deceptive functionalities, and participants reflected on and reacted to these in semi-structured interviews. The following themes resulted: effort & complexity, strategies/channels, privacy & control, authenticity & personas, social signalling & empowerment, access control & audience, ethics & morality.
This section has been adapted from work published as Computationally-mediated pro-social deception at CHI 2016, with Max van Kleek, Dave Murray-Rust, Keiron O'Hara and Nigel Shadbolt. Beyond early brainstorming I did not contribute directly towards the designs of the vignettes themselves, but participated equally in the questionnaire design, carrying out interviews, and coding and analysing the responses.
Introduction
Relevant background about deception in the context of online self-presentation can be found in chapter 2. The use of deception as a technique for system designers has been discussed previously within the HCI community. For example, manipulation of users' mental models of systems in ways that benefit both systems' designers and end-users were documented by Adar et al. [adar2013Benevolent]. Ambiguity, often promoted through deception, gives people space for flexible interpretation [gaver2003Ambiguity], and to tell stories they need to in order to preserve face and reputation [aoki2005Ambiguity, birnholtz2012distance]. However, the complexity of modern social software dictates that a growing cast of actors be considered, both human and computational, as targets, confederates, dupes and adversaries for any action.
We base our use of the term 'deception' on McCornack's information manipulation theory [mccornack1009InformationManipulation], which encompasses both falsification and selective disclosure, such as for the purpose of creating ambiguity, or identity management.
Context and research questions
Here, we are interested in exploring the complex contexts in which deception might take place, to consider not just cases where the system lies to a user [adar2013Benevolent] or computer mediated communication where one user lies to others, but situations where systems lie to each other about users; where a user needs to lie to one audience but not another; where tools or systems might protect a person from disclosure to other systems or tools. As Nissenbaum puts it:
Those who imagined online actions to be shrouded in secrecy have been disabused of that notion.
As difficult as it has been to circumscribe a right to privacy in general, it is even more complex online because of shifting recipients, types of information, and constraints under which information flows.
We have come to understand that even when we interact with known, familiar parties, third parties may be lurking on the sidelines, engaged in business partnerships with our known parties. [nissenbaum2004privacy]
The actors involved now include not just the people who are being immediately addressed, but others who are peripheral or incidental to the interaction as it occurs. Many systems include silent 'lurkers', who observe without speaking. Others will discover and read conversations later, outside the contexts of their production. Beneath the visible surface of the communications tools people use, a growing series of actors mine the interaction data which occur on their platforms, and still others use the results of this mining. Many of these actors are computational systems of increasing power, sifting, sorting, re-purposing and inferring from the full spectrum of communicative data.
How might sophisticated privacy tools in the future facilitate greater end-user control of personal information through obfuscation and deception? What might be the personal, moral, and ethical implications of the use of such tools online? In this section, we explore these questions, and provide the following contributions:
- An expansion upon previous models of computer-mediated social deception with new configurations, in which tools conduct or facilitate deception towards other people/systems/tools;
- A description of a speculative design experiment in which reflections on fictional tools for social deception were elicited;
- A characterisation of the practical and social perspectives on the use of such tools, along with design guidelines for future tools employing deception in social contexts.
Study Design
Method
We sought to elicit diverse perspectives and experiences from people from a variety of backgrounds, around various deception configurations. Drawing inspiration from critical design [bardzell2014reading], we adopted a speculative design method in which we first generated a series of speculative design proposals [dunne2013speculative] consisting of realistic depictions of imagined, 'near future' privacy tools. These fictional privacy tools, with accompanying descriptions, which will henceforth be referred to as vignettes, were then showed to participants in semi-structured interview settings.
Interviews were conducted in person and via video chat. At the start of interviews, participants were asked an opening question, How do you feel about your privacy online?
which was used to gauge general attitudes and sensitivity towards privacy online. Then, two framing questions were asked during the interview for each vignette; the first was whether the individual would consider using a tool like the one described (and why/why not), and second, whether the ways they perceived others and information they saw online would change if they found out their friends were using a tool like the one described. Finally, participants were encouraged to share thoughts or personal experiences that they were reminded of by the vignette.
Audio from sessions was recorded, transcribed and anonymised for identifiers of people, places and entities. Inductive thematic analysis was carried out on the transcripts by analysing and coding them for themes, by three researchers independently. Themes were then compiled, combined into a single pool, and discussed to derive a final coherent set of themes. Related themes were then clustered into groups. We organise our discussion of results according to these clusters.
Participants
We recruited participants via Twitter, open Facebook groups, and word-of-mouth through personal connections. Those interested first answered demographic questions covering age, gender, employment status, frequency of use of social media, and self-perceptions of honesty. Fifteen participants (aged 18+) were selected in a way that maximised diversity over the attributes collected.
Designing the vignettes
The vignettes were selected from an initial pool of sketches according to:
- the degree to which machines mediated the deception;
- the "balance between concreteness and openness" per Gaver's Conceptual Design Proposals [Gaver:2000:AEI:332040.332433].
We wanted to aim for tools that would be realisable in the near future, inspired by Auger’s speculative designs: speculative designs exist as projections of the lineage, developed using techniques that focus on contemporary public understanding and desires, extrapolated through imagined developments of an emerging technology
[auger2013speculative].
We preferred simpler, plausible vignettes to encourage participants to focus on implications rather than the tools themselves. See figures 10-14 for the vignettes used.
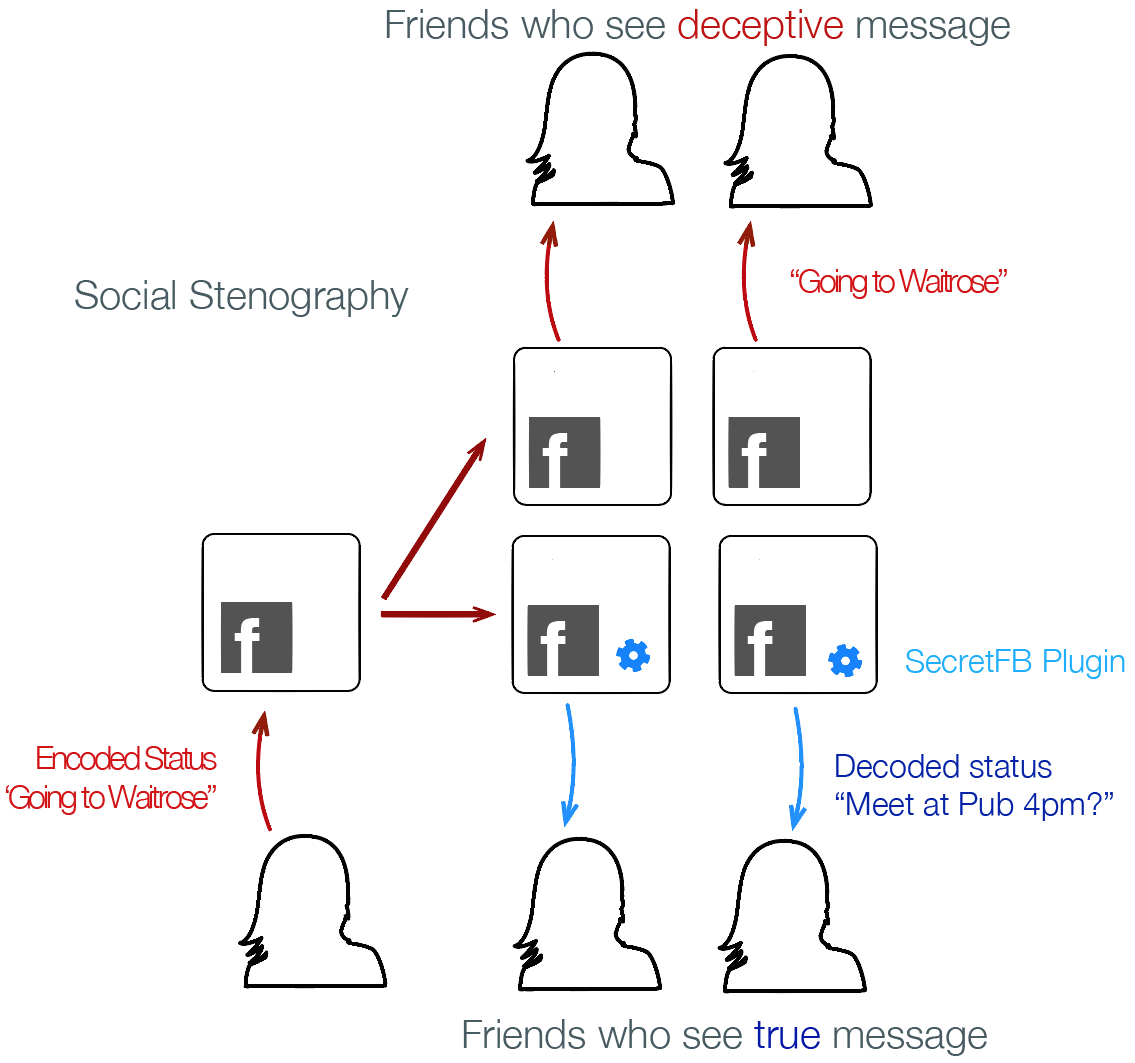
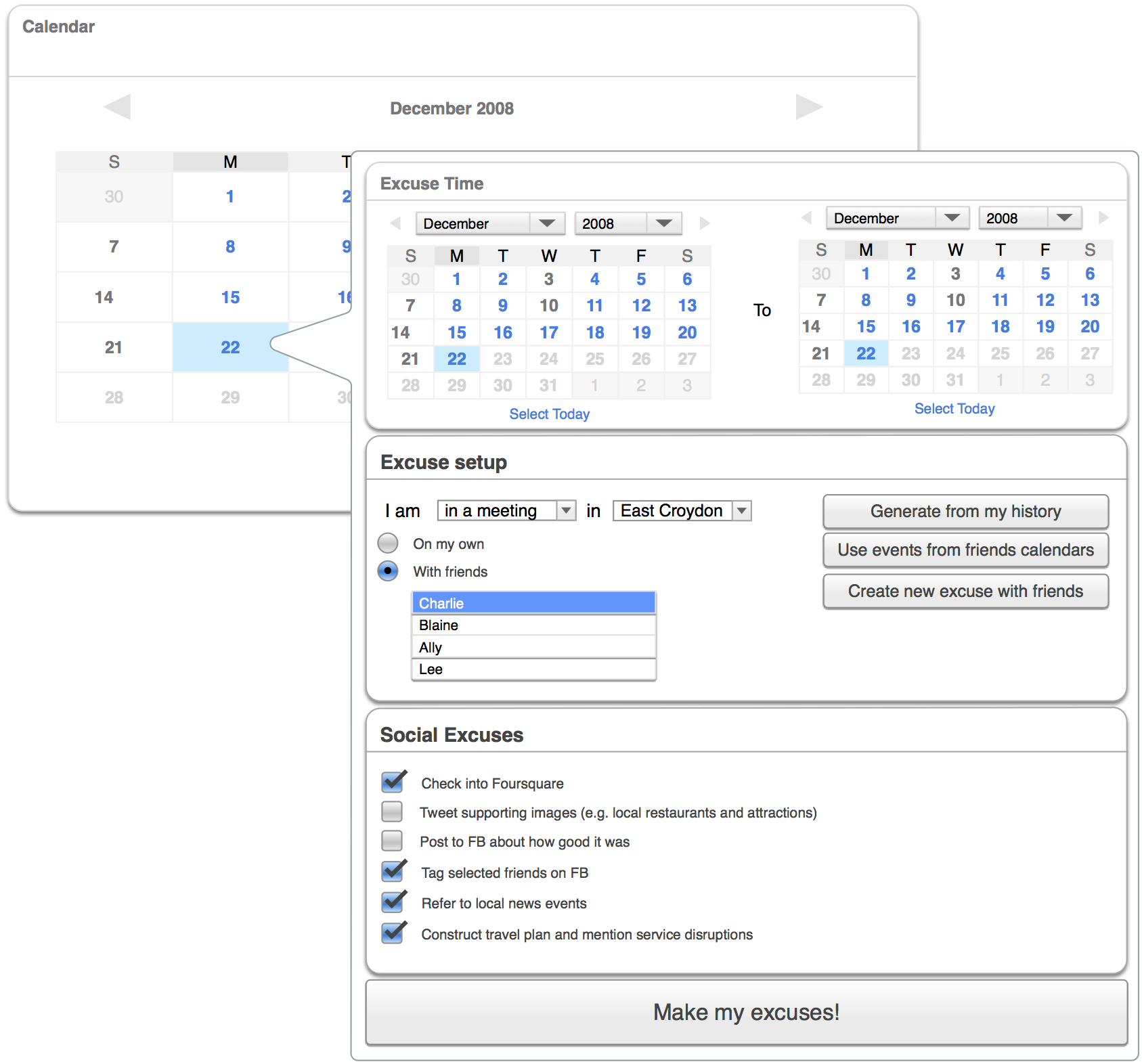

- Social Steganography, inspired by danah boyd's studies of networked teens [boyd2014s] who used in-group codes to discuss activities so that they were inscrutable to their parents. Here, the steganography is performed automatically: a trusted set of people see the 'real' message, while everyone else sees an 'innocent', socially plausible message.
- lieCal can automatically or semi-automatically fill one's shared calendar with fictitious appointments based on past (and typical) daily schedules, to create ample opportunities for butler lies. Friends can be enlisted to give support to the lie, and additional corroborating evidence can be posted on social networks.
- lieTinerary draws on Merel Brugman's Same Same But Different, enabling the pre-curation of a fictitious trip or fictional event attendance through pre-scheduled, coordinated posts across multiple social media platforms.
- lieMapper shows the interconnectedness of communication channels. Extending Facebook's 'this post will go to X people' functionality, it works across multiple networks to visualise all those within one's friend networks likely to hear about a particular piece of information.
- lieMoves is a fictional service for mobile phones that replaces the user's actual location with data from user-selectable and customisable deception strategies: blurred (low-grain), superposition of locations, past replay, or 'typical herd-behaviour or individual simulation.
Results
In the following sections, we first present detailed case studies of three participants (P8, P9 and P13) to illustrate how individuals' attitudes towards privacy influenced their answers to some of the vignettes. We follow these descriptions with a presentation of themes derived from all participants.
Participants
Assuming they reported truthfully, the 15 participants we selected covered most of the major attributes in our demographic categories. One notable exception is that all participants identified as either male or female, and almost half of the participants were males aged 22-30. We did not collect information on race, sexuality or any other attributes which might be used to identify marginalised groups.
11 participants reported that they used social networks several times a day, and all but one believed that half or less of their real world activity was represented on social media. 11 agreed or strongly agreed that they saw themselves as honest, but only seven agreed or strongly agreed to seeing themselves as honest online. Nearly half agreed that they thought their friends were honest.
As additional background, we wanted to gather the 'paranoia' levels of our participants and used Westin's categories (see chapter 2) to understand the responses. 13 reported being at least somewhat concerned about their privacy online. According to responses to the opening question, slightly over half fell into the Westin category of privacy pragmatists, while two fell into the category of privacy fundamentalists, and the remaining four were unconcerned about privacy. (High inter-rater agreement was achieved for this category; Fleiss's k=0.624 for 3 raters and N=15 participants). These results show that in comparison to Westin's large survey of the American public [krane2002privacy], which had a respective breakdown of 55%-25%-20%, we had relatively few privacy fundamentalists among our participants, and slightly more of those in the unconcerned category. However, a meta-survey of privacy indices show that our proportion is comparable to more recent results [kumaraguru2005privacy]. In other words, we have a sample fairly reflective of the general US populace.
Case study: Privacy and people (P8)
P8 is a former gradeschool teacher who has returned to university to get her Ph.D. She started using social media ten years ago when she was still working at the school, and her role as a teacher strongly shaped how she managed her exposure online. Specifically, her role led to caution in disclosing too much personally identifying information, but she acknowledged that disclosure itself was important for fostering relationships and participation online.
When I was a teacher, I was very careful about what I said about teaching in school because at that point I'm not just 'me', personally; I'm also 'me' as a teacher, representing that school I was working at. Since I've stopped being a teacher, I unlocked my Twitter feed, but still try not to post too much personal stuff online. But really, if you don't share some personal information then you miss out on so much interaction stuff, so it's a real balancing act.
She kept her Twitter feed primarily for her professional colleagues, and her Facebook contacts for her offline personal friends. She believed that, as a result, most of her interactions were with honest people, and tried to be as honest in her interactions online as possible, just as in real life.
When discussing lieTinerary, she described discovering that her ex-partner was fabricating extravagant holidays after their breakup in order to make her jealous.
[H]e wants me to think, 'Oh, I should have stuck with him — he's having a really good life!'. So there were pictures he was putting up [on Twitter] which were supposedly where he was on holiday, but of course once you know how to scrape people's Twitter data, you could see all of his posts were made in the UK. And at that point it became really obvious that that's what he was doing, so that made me smile. But that's the only case [...] he's doing it purely because he likes to think I'm reading them, and of course I have dipped in and have had a look and had a bit of a laugh about it.
She described wanting greater controls to be able to block said partner from getting around creating new profiles to look at her information:
I do know that, if he really wanted to he could easily set up another account. So in the end, although he's blocked [on Twitter] I don't assume he can't see what I'm saying; I assume that he can, and that's another reason that I'm a bit careful with what I say. So I wish it was easier, to stop people from being able to see what you're doing — how that would happen I don't know — but that would be really helpful.
Case study: Honesty and self-image (P9)
P9, a 22-year-old recent graduate, confessed he was very concerned about the availability of the data he gave out online due to a mistrust of companies. Valuing honesty, however, he said he would feel guilty using tools that would cause other individuals to be deceived, especially if those tools left digital interaction traces that could serve as later reminders of such acts:
I feel like I'm told that I have a certain level of privacy, I don't quite ... know enough about comp sci or technology to properly have faith in that. Like Facebook, Microsoft ... all tell me I'm safe online, and I might understand a bit of what they mean, but there isn't a great deal of explanation and I still think there are people out there who can get access to this stuff if they really wanted to.
With respect to how he manages his personal information, he prefers to be honest and transparent when the asking party is a person, even strangers online, but adopts a strategy of omission or falsification when the asking party is a company.
I'm quite an honest person, [...] like if I was on a forum and I was talking to someone I'd tell the truth. But if a company were to ask me for my number or my name — I won't bother.
I imagine [lieCal] would be useful because it would give me an excuse if I wanted to do something, but I would probably feel worse ... because it would serve as a reminder that I lied
However, he was confident there were others online that consider using tools like lieTinerary to promote themselves and make themselves appear popular or cool, such as by pretending to go to exclusive events:
Well they might use [lieTinerary] to come across as fashionable or trendy — they might put up a post like 'oh yeah I'm at London Fashion Week' when they're not really [...] I could say I'm at Glastonbury for the weekend, and immediately my cool points would go up.
P9 believed that such fabrication was widespread already even without such tools, alongside acts of playing one's self up:
I know people who have paid for likes and followers and stuff and they hashtag everything to death because they're so desperate for attention [...] there are lots of people nowadays who just want quick success and they'll take all of these cheap, cheating routes.
Case study: Privacy and technology (P13)
P13 is a postgraduate student in his mid-twenties; technologically savvy and uses social networking sites every day. He is acutely aware of the volumes of data being collected through his web use, but finds himself weighing up the practicalities of taking steps to preserve his privacy with his immediate communication needs, often concluding that life's too short
to act on his discomfort around third-party software.
I say what I'm doing on my Facebook because otherwise no-one will ever talk to me [...] I try and use small bits of privacy enhancing stuff, to whatever extent they actually work [...] So in the past I've had Facebooks where they're not tied to my... my lying even extended to that and all the information on them was fake. Nowadays I tend not to do that because the net effect of that is no-one talks to you.
He takes steps to manage who sees his data on social media, by segregating his audience by platform, choosing who to share which aspects of his self with, and using privacy settings built into the platforms themselves. Sometimes this leads him to obtain information by proxy:
I don't connect to my mum's stuff and I don't want to connect to her stuff [...] but I wanted to find something out and so I remember asking my sister to look it up for me.
He is also resigned to data leakage, and being surveilled, by both the government and advertisers.
if it's online it's public to a certain degree right, it's... you can try and use all these controls to a certain extent, but they don't... there's always a way around things. It's like, when you're a kid and you're trying to listen to the radio and you're trying to store it cos you want to listen to whatever the thing is again. You know, theoretically they've got these measures that say oh no you can't copy this, but you stick a mic out into a cassette recorder and you've got the Hitchhikers Guide, and hey.
I don't think I'm under any illusions about web stuff. If it's out there, it's out there. If someone wants to find it and knows the information or ways to get the information then they can get it. It's annoying, but it's a fact of life.
This does not stop P13 from providing false information to services whenever he has the opportunity, under the impression that the data many services ask for is superfluous. He speculated that tools could be useful to generate more believable false data on his behalf.
So for instance airport wifi. I spend a large amount of my time in airports. So I think I'm listed as John Smith ... in Edinburgh airport, different email address, different contact information, and yeah, so we start to lie about [...] So mostly it's whenever these anonymous websites want some personal information that they don't tend to have, then I tend to lie [...] But I always sort of wonder, should I be able to generate this?
In general, he was concerned about the social risks of using tools to aid online deception, especially when you can do this social ways, just going, oh I forgot to use the Google calendar again
but was also skeptical about how much he could trust the tools themselves.
If [social steganography] was something that I could run on my computer and I'd have it disconnected from the network then maybe.
Despite his concerns, P13 expected that he would follow the status-quo if many people began using these tools, and expressly supported other people's right to use them, reasoning that the more people did so, the more effective they would become. However, he also anticipated that the output of the tools may be prone to detection and thus rendered useless.
You could imagine someone attacking these kinds of things and trying to start to write distinguishers for when is this posted by a human or is this posted by a social media bot.
Effort and Complexity
A common reason why participants wouldn't use these tools related to the amount of effort required to use them. P8 observed that the effort-of-use barrier is a challenge even for tools already available today, and postulated that platforms were exploiting the lack of adoption of these tools to their advantage:
The thing I've noticed is that people will always do the easiest [thing]. That's why nobody encrypts. I don't. You know, for all my concerns about privacy, I don't encrypt anything, [...] very few people take the extra security steps they can because it's convoluted. And the minute you ask people to do that, they'll just take the easiest route. Providers like Facebook and Twitter and all the apps out there know that, and that's why it's so easy for them to collect data — they know people will just take the easiest route. — P8
However, for some vignettes the extra effort was seen to pay off as an opportunity. For instance, in response to Social Steganography, P6 contemplated that by broadcasting different status updates to distinct subsets of his friends on Facebook, he could control multiple identities simultaneously:
I think essentially at this point you are projecting two identities simultaneously and you really would want to manage both. [...] it almost becomes twice the task. But the really interesting thing would be if different groups all had different keys — so you'd send a single status but they'd all see different ones. That would be sort of be neat, [to be] projecting multiple identities at once, because you can't really do that offline. Finally, technology would give us a chance to BETTER control our identities! — P6
A second aspect that was mentioned was not the direct effort of use, but the effort that would be indirectly required to stay on top of the wake of deception left by using such tools. In some settings, participants noted specific compensatory measures that would be required to prevent being found out, and noted the complexity and effort of these measures.
If I used a tool like this and said I had been in meetings but then actually NOT logged the hours against the project, what the meeting was about or anything like that, it would make my accounting for my own time very hard. — P7
Availability of Other Channels, Strategies
The most common reason given for not needing to use a tool was the availability of alternative approaches to achieving the objectives for which the fictional tools were imagined to be most useful. A common such strategy was for individuals to simply omit or suppress information they did not wish to share; this strategy was used for a variety of privacy-related concerns as an alternative to use of the tools depicted in the Social Steganography and lieMoves vignettes. A second common strategy was the use of other channels and access control features. For instance, P13 discussed the use of encryption to both help control scope of a message and for unwanted leakage by platforms. Several mentioned Facebook and Google+'s built-in access control features for limiting the scope of a particular message as an alternative to using a steganography approach.
In some cases, participants identified that alternate strategies were imperfect, and sometimes the fictional tool offered a better solution. For example, the alternate strategy of suppressing location leakage by turning location tracking off, was perceived as worse than lieMoves by both P6 and P9, because doing so would cause apps that needed the user's location to simply refuse to work.
There were fewer alternative strategies given for the other vignettes; simply being honest
, and in particular blocking off time
was given as a common strategy for situations where lieCal would be useful (P4, P8, P9).
Privacy and Control
Several participants cited potential benefits to privacy control and management. The leaking of location information was a concern; six participants reported keeping location services on their smartphones turned off by default for reasons such as to prevent apps from sending their location to third-parties without their consent.
[lieMoves] would mostly catch out apps that were taking my location without even asking, because if I want to tell the truth when I think it matters, I can still do that, but those that are just spying on me gets crap! And that appeals, because they shouldn't be able to collect in the first place! — P6
P8 asked whether lieMoves was available for use, because she wanted it immediately to keep Google from tracking her.
I want to install it immediately and keep using it for the rest of my life! I wouldn't have any ethical worries about it because I wouldn't be lying to anyone, I would be lying to Google, and that's exactly what I want to do! Because they shouldn't have this information in the first place, so giving them wrong information is perfect. As I said, can I have this today, please? — P8
Others pointed out that a remaining impediment to adoption of such tools is still a remaining lack of awareness of how services operated and used people's information.
People can't make value judgements about the systems they interact with because they don't understand them well enough yet, especially what's going on behind the scenes. They don't actually feel the need to deceive system and platforms because they don't even know they're being spied upon. — P6
Authenticity and Crafting Personas
Participants reflected on how the data they shared affected other people's perceptions of them, as well as their perceptions of others on social media. P11 (in agreement with P1, P2, P3, P6, P7, P8, P9, P12 and P15) assumed that her friends engaged in image-shaping
by being quite selective or trying to present a particular kind of persona
, and described an occasion when a contact's online presentation was at odds with what she knew to be happening offline.
People will always seem like they're having a really good time and post about how great everything is but then you talk to them and things aren't actually quite how they're made to be portrayed on social media. [...] So like one of my friends, her sister was just posting about her one year anniversary of getting married, and how brilliant it was, and they were both posting about the presents they got for each other. Within a month they were separated [...] I know more about that from talking to my friend personally, but in terms of what's presented online to a different audience, to a much wider audience, that was not what was going on. — P11
P12 described a friend who, unable to withhold information or resist questions from an inquisitive audience, made up stories about her life to satisfy them, thus creating a persona.
'Cos of the following that some fanfiction gets, she gets asked a lot of personal questions and she doesn't want to feel rude so she just lies, so she answers these very personal questions so she feels connected to her audience but she deliberately lies 'cos she finds it sometimes a bit invasive. — P12
P8 and P15 similarly mentioned deception used to protect privacy without alienating people. In contrast, others saw total openness in their sharing as important for presenting their "authentic" selves on social media, and thought less of those who they perceived to be engaged in deliberate image-shaping.
I wouldn't be friends with people who would be lying all the time or who make up stuff just for attention. [...] if I found out that there was someone I was interested in doing this the faith I put in them or the fact that I was being very genuine would take a hit. — P9
Polite Social Signalling, Kindness, and Empowerment
Though sometimes in conflict with attempts at authenticity, a number of respondents echoed the sentiment that degrees of deception are crucial for maintaining a well-functioning society.
I think that not telling people — everyone, everything — is a central aspect of being kind in the world. — P15
It's about empowerment — little lies, like
I'm just too tired and you're quite a taxing personcould be the truth but that's a bit mean, and you didn't want to say that! versusoh no sorry I have plans with my boyfriendwhich might be a lie, but it's nice. — P6
Often you lie to save people's feelings or — to stop someone finding out about a surprise party. Like there are really nice reasons to lie, and if you could help people make nice lies safer, that would be awesome! — P14
P6 commented that this could be a subtle method of signalling violations of personal privacy online:
The idea of being able to put massively sarcastic calendar appointments just so that, when someone looks at my calendar to see what I'm doing, they know I don't want them to know, and they should just stop asking. — P6
Such methods were also viewed as a form of social empowerment; a way of giving people freedom to block off time (lieCalendar) or send a message (Social Steganography) in situations where the honest approach would be awkward due to shyness, introversion, or differences in social positions, e.g. having to contradict a superior or respected senior.
Somebody younger, less experienced, less confident might find that this is a nice, straightforward way of blocking time out for themselves and feeling good or comfortable about it. Because it can be quite difficult saying
no, I'm not freeto someone senior. — P8
Access control and imagined audience
Many participants discussed their expectations of who could access their social data and messages. P15 and P11 mentioned assuming private Facebook messages could be read only by the recipient; all but four participants segregated their friends using platform privacy settings.
If I wanted only certain people to know something I'd just send them a private message rather than put it as my status anyway. — P11
Very occasionally I will post things only on Facebook and not Twitter because then only my friends can see it. — P6
Why would I need such a tool when I can define on Facebook, for every single message exactly who sees it? — P7
Contrarily, several participants also rationalised that they must assume that anything they post online could be made completely public at any moment, and the safest technique is not to share at all.
If there's something you don't want people to know, then you just don't tell. — P7
P12, meanwhile, said lieMapper would potentially improve her ability to maintain separation among her separate personas online by showing her when information from multiple identities linked up.
This one is more just a way for you to control your privacy [...] Cos I don't actually have anything linked directly [between identities], but probably they have certain things links other ways, so that would be quite interesting to see. — P12
P2 and P14 were among those who considered themselves not interesting enough for anyone to want to invade their privacy, and P4 even found it felt quite good
when he found his private facebook profile had been accessed by someone outside of their network because he was of interest to someone
.
Ethics and morality
Finally, many of the participants volunteered their views on ethical or moral reasons of why they would or would not use these tools in specific ways. Perspectives varied in general and according to the vignette presented.
The technology vignettes could be seen as ethically neutral, with the ethics coming from the manner of their use:
If your intention is to use these tools to harm someone, then that's the individual's own decision to make and you can decide for yourself whether that's morally right or wrong. But simply using the tools themselves doesn't imply you're going to do something that is harmful or morally wrong. — P5
However, in some cases, there was such a strong correlation between the design of the tool and the kinds of lies which it facilitates that the morality of the tool became the morality of the action:
Well as someone who's considered murdering people before, this is exactly how I would do it. I would create a fake social media presence so I could go off and do something illegal or even ... I could commit adultery, I really can't see much of a practical application for ethically good things... — P14, discussing lieTinerary
To P6, whether deception was moral was contextually dependant on whether the recipient had a legitimate need for the truth and why.
If someone has a right to know something for some reason [...] then lying to them there is more problematic than if they didn't have a right to ask you, or to be looking for that information. [...] that's their own fault; they should have know they shouldn't have looked. — P6
Some participants suggested that they would need a really good reason to use deception tools. P14 felt that a better alternative to having to lie was to get out of situations in which one felt the need to lie.
And if you're in a situation where you have to lie to people about where you are, then that's a situation you need to get out of cos that's a creepy situation [...] The only time I can see this being good is like if you're in an abusive marriage and you're going to a divorce lawyer in secret. — P14
There was often a moral distinction made between friends and platforms as the targets of deception. A majority (11) took issue with deliberately deceiving friends and there was also widespread consensus on wanting not to deceive a general audience on social media. By contrast, there was a feeling that lying to platforms is not dishonest.
well if I'm talking to my friend I always tell the truth; I'm quite an honest person ... but I don't think lying to Facebook is unethical [...], because it's not affecting any of your friends or anyone on your list, so it has no effect — so you're not really lying to anyone? [...] I don't trust these companies enough, to be honest, with the information I supply them. — P9
P6 took the position that lying to platforms should be the moral choice, even part of one's civic duty.
I think lying to Facebook is to be encouraged! [platforms] spend so much effort in deceiving users into thinking they're doing one thing when they're doing another, that giving users some control seems fine. Its sort of like the debate whether minorities can be racist against white people — like, whether the power imbalance seems to negate any meaningful argument, certainly when it comes to lying to services. — P6
Discussion
Deception is a long-established strategy for informational self-determination, and it is not a surprise to see the practice in online behaviour. The study reported here is a necessary preface to the deep study of deception, and establishes interesting lines of enquiry which mark out a descriptive vocabulary and a potential design space. Nissenbaum outlined the importance of contextual integrity for online design, the idea that individuals bring a set of expectations and meanings to their online interactions that are often derived from offline analogues, appropriately or otherwise [nissenbaum2009privacy]. A designed interaction that leaves no space for someone to present themselves creatively for non-malevolent purposes fails to preserve contextual integrity, and would consequently produce an asymmetry of understanding between user and system of which the user may be unaware.
Deception is often an expensive strategy, involving some creativity, the avoidance of passivity and the maintenance of consistency in an alternative narrative. In all but its simplest forms, it is not something that most people do lightly. Particular strategies and opportunities for deception were common to many of our subjects, who were often concerned with the balance between the moral injunction against lying, and their own interests. Mitigating factors were sought: for example, if the counterpart in the interaction is non-human (a platform, for instance), or if the interaction provided an opportunity for malign activities (e.g. could be used by a stalker), or if the counterpart did not have a good reason for requesting the data, then these were seen as justifications for using deception for protection.
Morality of Deception
Our participants, like the majority of people, like to think of themselves as being generally honest, but this has a nuanced relationship with their reported behaviour. There was a common feeling that deceiving platforms and corporations was acceptable, or even a moral imperative. Nomenclature was significant: casting activities as 'lying' provoked responses which paid more attention to the ramifications of being found out, and a greater sense of ethical violation. However, 'hiding information' was generally seen as acceptable, as was partitioning information for different audiences, especially in the context of avoiding unwanted attention. Politeness was often cited as a valid reason for performing white lies, a variety of kindness.
Akerlof and Schiller's account of phishing [schiller2015Phishing] focuses on deception from the point of view of corporations, and therefore helps explain the existence of situations in which our participants were motivated to deceive. In the information economy, data subjects are beguiled, misled or strongarmed into giving away more data than is required for the service they wish to access. However, perhaps because their focus is wider than the information economy, Akerlof and Schiller fail to consider the possibility of the individual creating counter-asymmetries by manipulating the data they provide to corporations. Their recommended counter-measures are all intended to support truthfulness — standards-setting, reputation, regulation. Yet these all require concerted action, while deception is a strategy open to the individual.
Memory, safety, and plausible deniability
It was clear from responses that being reminded of one's lies can be upsetting, especially for people who consider themselves honest. On one hand, this suggests that systems might automatically remove, or reduce the visibility of, digital traces that could serve as reminders of one's past deceit. The recent growth in messaging apps that automatically delete messages after a single viewing [messaging2015] might, in fact, be related to this perceived design need. On the other hand, visibility of such actions can lead people towards greater honesty — knowing how often one was deceptive could clearly be a powerful push towards veracity.
A second major theme addressed the effort, both of using the tool, and dealing with its potential consequences. It was clear that any tool that required more time and effort than customary was perceived as too burdensome. There was also the consideration of the side-effects caused by such tools, and the degree of effort required to ensure such repercussions would not cause deceptions to be discovered. But having to explicitly act at all was also viewed negatively; that is, having to engage with a tool in order to carry out a deception, such as with lieCal, was viewed less favourably than something that could do it automatically, such as lieMoves.
An additional problem with requiring users to carry out an explicit action is that doing so often leaves little space for plausible deniability: it becomes often difficult to maintain that such an action was taken accidentally or unintentionally (assuming the individual is of sound mind). If we instead imagine tools that deceive by default, the possibility that a deception was simply a side effect of being busy or forgetting to make the system tell the truth would remain. For example, a deceive-by-default variation of lieCal might automatically fill the person's calendar with false but plausible appointments, allowing its user to quickly identify and replace them with real ones as needed. Such designs would additionally support many of the goals of privacy-by-design [schaar2010privacy].
Another significant barrier to the use of such tools is related to safety and discovery. The first: ensuring that deceptive actions would not have unintended consequences, while the second pertains to the effort and actions necessary to ensure deceptions would not be discovered. Such concerns suggest that there is a potential space for future tools that are able to support safe deception, both in terms of highlighting potential hazards, and towards mitigating the burden of covering up active lies and their effects. Tools such as lieMapper that are able to provide situational awareness about social information flow could help individuals tell certain lies, especially nice ones (as described by P8), with less risk of exposure.
Design implications
Despite the preliminary nature of this study, the results suggest many questions for consideration by system designers. Those providing services for data need to identify, respect and avoid the factors which lead users to deception. The act of deception creates a situation in which data minimisation is in the interests of the platform — the less that it asks for, the more likely it is to be trusted, and the less likely the deception strategy is to be invoked. In particular, contextual integrity is preserved if users are able to represent themselves differently in different contexts, and it is clear to them that the more data that is demanded, the easier it is to resolve these personas. Similarly, there is a set of deceptions, such as butler lies, which are adapted to specific communication situations, and facilitating these will also help transfer and preserve expectations in the digital context.
Systems which facilitate deception will have both positive and negative potential. Most obviously, their wide uptake would reduce trust in data generally. On the other hand, it is clear from our study that for most people, deception is a last resort, that is, the majority self-image is one of general honesty so that deception would demand ad hoc justification. A rather more calculated invocation of a deception system might, if such attitudes were widespread, be a step too far. Framing the objective of the system will be key — for example, classifying such systems as privacy-enhancing, rather than deceiving, might increase their acceptance. However, software that maintains a consistent, false record of events might remove the burden of understanding for users that their behaviour is deceptive, thus making it easier to deceive. Such divergent potential outcomes require investigation.
Contributions to the 5Cs
The themes that emerged from these interviews mostly serve to expand our understanding of the contexts in which people interact online. The ethics or general acceptability of deception varies depending on the moral standpoint of the respondent; which is likely developed by their immediate and cultural environment. Technical contexts were raised regarding the ability of tools to retrain traces of lies as well as the fact people often don't understand how the tools they use actually work. Tradeoffs between being fully honest online and just not participating at all are also a function of the social environment (ie. it may be acceptable neither to avoid online interactions, nor to be fully authentic, leading to some form of deception as a necessity). The alternate strategies discussed reminds us that people use many tools and systems in conjunction, and these uses influence each other. This is part of a personal context.
Wishing to have plausible deniability, as covered by effort & complexity, as well as the strategy to omit information or use privacy controls, all feed into our notion of control.
Engaging in image-shaping and other social signalling may require some level of customisation.
Participants demonstrated their awareness of audience - connectivity - in responses about access control and the morality of deception depending on who is being deceived.
Concern about information flow around a system was particularly highlighted by the lieMapper vignette. The idea that everything one puts online might become public, concern about being tracked by third-parties, and traces of deception being persisted by systems, all feed into the cascade aspect.
The 5 Cs of Digital Personhood
The studies in this chapter span a variety of different perspectives, technical systems, and use cases. Each bring to light certain considerations around online profiles or self presentation. Here, the results of each study are summarised and briefly discussed. I clustered the results of each study according to similar components (see Table 11). The clusters make up the overall framework of five concepts which can be used to organise ideas around digital self-presentation whilst keeping track of different perspectives and influences, and acknowledging the interconnectedness between them.
What is a profile? describes affordances of systems which integrate online profiles in a social capacity and raises five features of systems with regards to their representations of users: flexibility, access control, prominence, portability, representation. These features in different combinations may empower profile owners more or less, and they reflect on how much authority profile owners have over the data that makes up their profile, what it looks like, and who sees it. The perspective of the profile owner is considered alongside the system owners/designers/developers, and other developers or third parties who can access and potentially influence profile information.
In Constructing online identity the focus is on cross-system profiles within a creative media production social machine. Where participation centers on generating and interacting with content, and participants have both more ability and more desire to experiment and entertain through their online profiles, we identify roles, attribution, accountability and traceability as critical dimensions along which to discuss self-presentation in these spaces. These dimensions reflect on the links between profiles within and across systems, the creative ways in which profile owners can visualise their identities, and how these representations are reused, remixed, and propagated throughout online and offline systems.
Studies about deceptive practices in online social interactions, The many dimensions of lying online and Computationally-mediated pro-social deception, a survey and interview study respectively, yield two sets of related themes about common usages of mainstream social media. The former results in system, authenticity, safety, audience and play as reasons people limit or modify their online self-presentations when compared to their offline selves. When individuals are asked to think more deeply about how they and others might mediate social interactions through technologies that help them to customise the 'truth', the latter uncovers concern about effort & complexity, privacy & control, authenticity & personas, access & audience, and social signalling & empowerment, when making decisions about when and why they would employ social deception techniques, as well as discussing alternative strategies for achieving the same ends without technological help, and the ethics & morality of doing so. These themes reflect on peoples' relationships with other users of systems as well as with the systems themselves — the extent to which people can oversee or manipulate how others view, access, and interpret their personal information; as well as the day-to-day social norms and expectations they are surrounded by before, during, and after their online engagements.
Finally, interviews with Social media makers delve into how individuals are maintaining online profiles without centralised services, motivated by self-expression, persistence/ephemerality, and authority, and constrained by the effects of their networks and audience consent. These themes reflect the importance of visual expressiveness in self-presentation and control over where data is stored and how it is maintained.
All of these studies demonstrate that online self-presentation is both constituted and affected by who sees a representation of an individual, and what it is they see, both of which are encompassed by the situation whereby it is seen (see fig 16). Next, I present the five terms which cover the possible lenses through which we must look at online profiles in order to understand them fully.
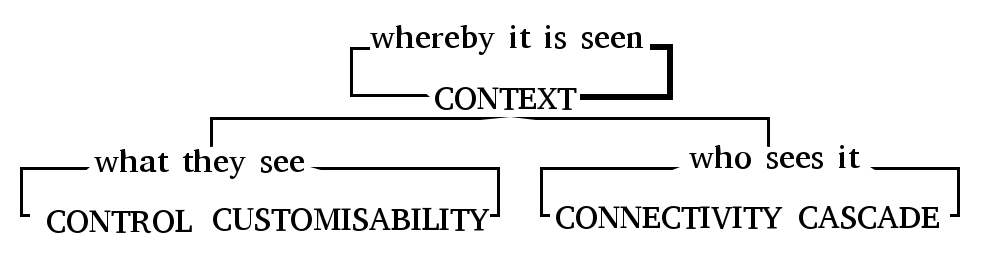
| Concept | Aspect | Study result |
|---|---|---|
| Context | technical affordances | S1 flexibility, S1 portability, S2 roles, S2 attribution, S2 system, s5 networks |
| social expectations, including participation | S2 roles, S2 attribution, S3 audience, S3 authenticity, S4 authenticity, S5 networks | |
| personal motivations | S2 roles, S2 attribution, S3 convenience | |
| policy constraints | S1 flexibility, S1 portability | |
| purpose of system | S1 prominence, S1 representation, S3 system | |
| avoiding danger/discrimination | S3 safety | |
| ethics and morality | S4 ethics | |
| being kind to others | S4 social signalling | |
| using multiple tools together | S4 strategies | |
| Control | create and discard identities | S2 roles |
| persistence vs emphemerality | S2 attribution, S2 accountability, S2 traceability, S4 effort, S5 persistence & ephemerality | |
| if a profile is required | S1 prominence | |
| ease of moving data | S1 portability | |
| how much of a person is a profile | S1 representation | |
| preventing context collapse | S3 audience | |
| diffusing awkward encounters | S3 audience | |
| malleable identities | S3 play | |
| avoiding danger/discrimination | S3 safety | |
| omitting information | S4 strategy | |
| understanding options | S4 privacy | |
| being kind to others | S4 social signalling | |
| consent (self and others) | S5 authority, S5 consent | |
| authoritative source of personal info | S5 authority | |
| decompartmentalisation | S5 networks | |
| Customisability | visual branding | S2 traceability, S5 self-expression |
| links to other profiles | S2 traceability | |
| how data is presented | S1 flexibility, S5 self-expression | |
| which data is shown | S1 flexibility | |
| to whom data is shown | S1 access control, S3 audience | |
| being oneself | S3 authenticity | |
| malleable identities / image shaping | S3 play, S4 authenticity, S5 self-expression | |
| being kind to others | S4 social signalling |
| Concept | Aspect | Study result |
|---|---|---|
| Connectivity | audience known/unknown | S1 access control, S1 flexibility, S2 attribution, S2 traceability, S3 audience, S3 authenticity, S4 audience, S5 networks |
| reputation | S2 attribution, S2 traceability | |
| purpose of system | S1 prominence | |
| claiming social space | S3 play | |
| multiple/cross-network audiences | S1 portability, S5 networks | |
| Cascade | aggregate profiles | s2 traceability |
| spread of information | S2 traceability, S4 privacy | |
| connections to other profiles / real life | S1 representation | |
| access to data by others | S1 access, S4 ethics, S4 effort | |
| context collapse | S3 audience, S3 safety, S3 system | |
|
Study numbering: (S1) What is a profile?; (S2) Constructing online identity; (S3) The many dimensions of lying online; (S4) Pro-social deception; (S5) Social media makers. |
||
Context
Individuals are situated in societies according to geographical, cultural, and familial boundaries. These societies vary in size and have different political, legal, and economic factors as well as social norms and expectations. We all navigate an intersection of different societies daily, some people more than others. Our identities are strongly influenced by what our societies expect (and demand) of us, and how we react to these expectations. Expectations of different societies can conflict, for example, when a woman is raised in a conservative religious household but in a country with a liberal non-theist culture, she may need to navigate different identities pertaining to her home life and work life. How we engage with identity online is of course impacted. A lack of geographical boundaries and a blurring of political and legal jurisdiction can complicate how individuals want to and are permitted to present themselves.
Despite the lack of geographical boundaries, the Web is not equal in every country. Governments censor particular systems, filter content, and surveil populations; organisations must adhere to different types and degrees of regulation around for example privacy and data protection. This too makes up part of the broader context in which digital representations of people exist.
These factors also serve to influence how technical systems are developed. From company revenue streams to subconscious bias of engineers, every technical decision — every feature added or removed — is framed by societies. This in turn impacts system users, who may exist in an entirely different social setting. The technology fundamentally affects what profile owners can and can't do; behaviors they are coerced or driven in to.
Not least, the motivations and day-to-day needs of individual profile owners constitute personal contexts. A single system may be used in ten different ways for ten different reasons — or even in ten different ways by the same user — depending on personal circumstance; profile owners are never homogeneous, and their situations are always changing. Similarly, people use multiple systems in conjunction, and these uses influence each other.
Control
Once an individual has established an online profile, how much authority do they have over the information collected and presented there? Determining whether aspects of a profile are emphemeral or persistently and reliably archived are important aspects of control of that self-presentation. Data entrusted to a third part may be lost — or sold — and cascade out of reach. Throwaway remarks may be indexed by search engines or snapshotted by Web archival systems, increasing the likelihood that they are accessed devoid of the context of the system or conversation of which they are a part and making it much more difficult to let go of or conceal a particular representation of oneself.
Whether certain personas or aspects of oneself are traceable, either to an offline 'real world' identity or to other online representations, is a function of how much control profile owners have over the connectivity of their profiles. Control is not increased by anonymity nor by a blue tickt of authenticity; either of these (or anything in between) could indicate greater or lesser control depending on other things (like the context). The amount of control available affects the extent to which profile owners need to customise their self-presentation, with regards to its presentation and access.
Customisability
For any given digital representation, an individual may or may not be able to adjust the information contained within. Profiles are composed of a variety of different data, and profile owners potentially have limited awareness of the data collected and processed about them. Certain data may be editable or deletable, or perhaps so for a limited time. Furthermore, profile owners may or may not be able to customise who sees which elements of a particular profile, depending on the levels of connectivity of the system they are using.
Online profiles can act as a proxy for an individual's physical presence. The customisation of online profiles also describes what the contents of a profile look (or feel or read) like, and can determine the impression others have of the profile owner, as well as impact how the profile owner feels about themselves. Just as one adjusts one's dress, posture, or facial expressions in person according to the particular role one is playing at the time (behaving differently with your friends compared with your teacher, for example), online profiles can be customised (not necessarily accurately) according to both known and imagined audiences. Customisation of profiles is strongly tied into the technical constraints or affordances of a particular platform (part of the context); less ability to customise may reduce a profile owner's ability to express themselves effectively, which in turn limits their control, or perhaps understanding, of the impression(s) given to their audience(s). Customisations can help profile owners to express individuality, or to demonstrate that they are part of a particular community or in-group.
Customisability also gives individuals the power to explore and experiment with different identities, whether these are closer to or further from what they feel to be their 'true self'. This freedom is important and healthy for many populations, including vulnerable or oppressed people, and minorities seeking connection and support from a geographically dispersed community. On the other hand, the potential to imitate others or hide one's identity in order to behave in malicious ways is also available.
On the other hand, more ability to customise self-presentation results in more decisions that need to be made by an individual, which can result in cognitive overload and perhaps be disempowering after all [crit12].
In contrast to the physical world, different aspects of an individual can be represented simultaneously by multiple online profiles. Whilst most people would avoid being on a date and at work at the same time, a dating site profile and an employment site profile can co-exist, and even be opened side by side by the same viewer. As one's self-presentation changes over time or with circumstance, snapshots of versions of oneself may be stored by search engines or Web archival systems, limiting control the profile owner has over their customisations.
Data from profiles may be displayed differently in different contexts, or in different systems, perhaps in ways which do not match what the profile owner intends or agreed to. Customisability may be lost through the cascade.
Connectivity
Systems have different affordances when it comes to connecting profiles together, both between different users and between multiple representations of the same individual. How connections are used and displayed within a system affects the imagined audience of a profile owner, and may impact how they need or want to customise their profile contents. Changes to profile information may propagate through a network to different degrees depending on the purpose of connections, and so connectivity is related to the cascade.
One's connections or social network can say a lot about a person, and so the connections themselves also constitute part of a profile. The prominence and semantics of these relationships varies between systems and communities, part of the context of profile use.
Cascade
The cascade corresponds to Goffman's expression 'given off' [goffman1959]; subconscious side effects of social interaction which nonetheless affect how one is seen or understood. In offline interactions, interpretation of expression 'given off' is typically restricted to the physically co-present (though they might pass their observations on later). With regards to online profiles, information about individual representations are propagated through and across systems: processed by algorithms, packaged, remixed, interpreted, correlated, aggregated, re-packed and oftentimes sold on, given away, leaked, or stolen. Many people know about the cascade to some degree, but most ordinary social media users are unaware of its extent. People have come to accept that Facebook sells their profile attributes to advertisers, but may not consider that Facebook can also make use of their mouse movements and clicks, visits to other websites entirely, learn about their life through running analysis on the text of their status updates, and may be legally required to hand over the contents of their 'private' messages if asked to do so in court (see context).
The cascade is also a function of connectivity; as friends, fans and followers get hold of one's profile, they can potentially share or repurpose the information beyond the original owner's control or knowledge. Thus unknown effects of the cascade can cause a loss of both customisability and control.
Conclusions and reflections
Through the five terms described in this concluding section, we can come to a well-rounded understanding of factors influencing the presentation of the self online. It is easy to forget or ignore the multitude of angles from which individuals are impacted when navigating networked publics. I propose this framework as a guideline for future work in both studying and designing digital social spaces, and hope that this helps both in terms of avoiding over-generalisations of social media users as we study them academically, and in terms of taking into account to a fuller extent individuals' circumstances as we make technical decisions about systems. The nuances of each term in the framework are explored in more depth in each of the studies presented here, although these by no means cover every possible angle; other angles are covered by other studies, reviewed in the previous chapter.
Of particular interest when it comes to building new systems (and developing existing ones) are the ways people 'misuse' features, or use them in ways other than system developers intended. Individuals and entire communities can appropriate particular features of systems to meet their own unanticipated needs; similarly, techniques for circumventing technical or policy constraints, or just 'breaking the rules' are widespread. Developers can learn from these activities, particularly if they attempt to understand their users as individuals who exist beyond and outside of a single system, and beyond the digital as well. I only hope that a greater understanding of system users leads developers to strive to better meet their users' needs, rather than improve their models of oppression.
On that note, the remainder of this thesis looks to decentralisation as a means for empowering individuals, and approaches this from a technical perspective. That is, taking the power out of the hands of centralised entities like the companies behind contemporary mainstream social networks, and putting it back into the hands of profile owners. Work in this chapter and the previous one illustrates to some extent how non-centralised, self-hosted, or individually-controlled personal systems (like blogs) increase the possibilities for individual aspects of identity construction, but potentially make it more difficult to integrate collaborative aspects, which are similarly critical for a complete digital self. Thus, we proceed to investigate the role of standard protocols for federating social interactions. Common protocols allow otherwise un-associated systems to work together without prior agreement, avoiding the lock-in that comes with the current centralised model. This brings, of course, a new set of challenges to address.
Social Media Makers
The previous three studies demonstrate that considerable effort is made by users of mainstream social media to circumvent constraints of the systems they use in order to better engage with other users, or to protect themselves from perceived top-down threats. But what of avoiding mainstream social media altogether? One of the systems examined in the first study is the Indieweb wiki. This is a particularly flexible, portable and representative way of managing profiles which does not rely on a centralised service or authority. The Indieweb community are amongst a growing number of Web users who are replacing or supplementing mainstream social media use with DIY personal social platforms. I call this kind of Webizen 'social media makers', and in order to compare this approach with our findings from centralised social media users I take a closer look at their activities and motivations in the following in-depth interview study. The results are that they opt-in to highly flexible and portable profiles despite technical costs, influenced by the following factors: self-expression, persistence/ephemerality, networks & audience, authority and consent.
Introduction
The Web today is a very different place than the one imagined by its creator, Tim Berners-Lee [weavingtheweb]. Instead of a vast network of individuals running their own web servers to host homepages or share information, most people simply navigate to Twitter to tweet, log in to Facebook to post a status update, use Wordpress.com to write up their thoughts. With a daily active user population of over 1.13 billion1, Facebook alone constitutes a full quarter of all Web traffic2.
However, there are individuals who in certain ways reject the massive social platforms that have swallowed the Web. Instead, they embrace 'home-grown' approaches to building their own web presences, much like the 'old days' of the Web. But unlike the old days, when such a presence might have comprised a homepage, 'DIY Web' hackers now piece together their own bespoke social and data management platforms, akin to the kinds of services offered by social platforms, for managing their interactions and identities online.
Often, such capabilities are realised by using an ensemble of open source tools and standards supported by developers with like interests. However, the various motivations for these individuals, and the perspectives they have gained from doing so have not, thus far, been studied extensively.
Context and research questions
In the previous studies we examined how individuals who participate in massive, centralised online communities present themselves and manage their interactions with an audience. In this section, we present a study which seeks to understand how individuals who avoid mainstream social platforms find other ways to present themselves online, as well as a descriptive characterisation of their digital spaces. We targeted a broad class of self-described digital makers: those who identify with taking a hands-on 'DIY' approach to meet their own immediate online social interaction and self-presentation needs. We conducted semi-structured interviews supported by live demonstrations of participants' own systems and their social media profiles, to address the following questions:
Study Design
With the wide availability of different social platforms, people often tend to use one or more to manage their online social activities. Different platforms are tailored to various types of preferences, philosophies and purposes, and target different communities and individuals' needs (social, professional, leisure). In this research we are interested in identifying and investigating individuals who desire the same 'type' of interactions that come through using mainstream social networking sites, but maintain their own platform (e.g. blog or website) as their primary online profile.
We designed interview questions to encourage participants to reflect on their activities, rather than just recount them. The intention was not to compare their experiences with particular systems, but rather elicit their motivations and habits, and ideas and feelings about the ways in which they interact online.
Participant Recruitment
From the existing literature (see chapter 2) we can see similarities and differences in habits and motivations of bloggers and social media users. What we haven't heard about are social media 'makers', who occupy some space in between.
Such individuals must be technically competent or willing and able to learn. They share the DIY attitude with maker communities who engage in physical/hardware hacking but in the purely digital realm. In the same way that hardware hackers seek to understand and control their physical day-to-day environment, digital makers who see social media as a core part of their everyday lives are engaging in similar practices online.
Social media makers are different too from the open source software developers who work on decentralised social platforms like GNU Social, Friendica, pump.io or Diaspora (these platforms are discussed further in chapter 4). That is not to say they are mutually exclusive and indeed many participate in several projects which are relevant to their interests in this space; but makers focus primarily on building systems which affect their own lives, and only secondarily address use by others.
I recruited suitable participants through distributing an online signup form in IRC channels and online forums known to be frequented by individuals engaged in building personal websites and social media systems, and asking those who responded to refer others they know. The signup form included a brief description of suitable participants so that people were able to self-select for the study.
The signup form asked for demographic information (age, gender, occupation, ethnicity, country of residence) as well as a list of personal websites and social media sites they use on a regular basis.
Method
Participants were asked seven opening or closing questions, and a set of five questions about each of their personal sites and each of their social media profiles, so the total number of questions depended on the number of personal sites and social platforms they used. I enquired about their motivations for building their own platforms, the particular functions they use them for, and about their audience. I asked similarly about how they use social networking sites, their audiences there, and how the functionality and audience overlap or differ between their personal sites and different social networking sites.
I conducted semi-structured interviews in order to gain a first-hand account of participants' experiences with building and using their personal social media systems. I used the list of sites and systems gathered during recruitment as a starting point and encouraged participants to click around their websites and profiles during the interview, and we recorded a screencast of the process. This served as a prompt for both the interviewer and participant which allowed me to tailor the conversation around the participant's particular experiences. It also aided participants in accurately recalling the systems they use, as well as backing up their anecdotes with specific examples from their personal sites or social streams. I also allowed participants to show and discuss sites they had not initially reported if they wanted to do so.
The interviews took place across a variety of different locations convenient to the individual participants. All but one participant used their own laptops when viewing their websites and social media profiles, so things were set up in the way that they were used to day-to-day. Participants were permitted to pause the screen recording and/or audio at any time during the interview if it made them more comfortable.
I used open ended questions as a guideline, but allowed participants to deviate freely to other topics if prompted by one of the questions, or something on their screen.
Participants were rewarded with a 15 USD gift voucher for their time.
Limitations
While a qualitative semi-structured interview is the appropriate method to gather people's various technology usages, motivating factors and associated examples, it also presents several challenges. Qualitative data gathering may suffer from a lack of detailed or accurate recollection of events; participants might report their perception of general trends instead of specific descriptions of their activities, and may be subject to unconscious influences or motivations. Participants may also deliberately withhold or distort information. Using this method some information can be misinterpreted or overlooked.
I mitigate against these issues as follows:
Since this target community is niche and at an early stage of development, and since my recruiting options were correspondingly limited, it is inevitable that the conclusions I draw from these results cannot be generalised to a broader population.
Analysis
I take a grounded theory approach to analysing the data gathered [strauss1990basics].
Immediately following each interview, I recorded pertinent words or phrases and notable highlights from the discussion, as well as a general impression. These notes were compiled into a preliminary set of codes in order to begin the process of identifying potential themes. I carried out inductive thematic analysis on the interview responses in several stages:
I organise the results section according to the derived themes.
Results
13 interviews were conducted in person, and 2 over video chat. 10 of these took place during or after one of three technical events, conveniently over the same week in nearby cities, which were of interest to and therefore well attended by our target participants during June 2016.
All participants work or study in the technology industry, which is typical of the target, though not all work in web development. 11 participants identified as male, 3 as female and one declined to answer. A majority of participants are white; two listed their ethnicity as Hispanic or Latino, one as Jewish and one as Asian, and two declined to respond. All are resident in North America or Europe. These biases are reflective of the technology industry and the routes through which we were able to recruit participants.
Interviews lasted between 45 and 90 minutes, and participants discussed between 1 and 4 personal websites, and between 1 and 9 social networking sites (mean 4.7). Some paused screen recording when typing in passwords or if they were interrupted by incoming chat messages when browsing social media. None paused the recording in order to show the interviewer something 'off the record'.
Participants talked about a combination of personal social experiences both on and offline, including how their online activities affect or are affected by their every day lives; their feelings about others working or experimenting in the decentralised social web domain; things they have accomplished and things they want or plan to accomplish in future; and technical details of systems they have built themselves. In many cases, participants naturally covered answers to the guideline questions without explicit prompting.
Across all of the participants there was diversity in both systems used and the main emphases of conversation, however there are many common threads around control and audience, which we discuss here.
The network
All participants maintained personal sites, and all used profiles on one or more major centralised social media services. All but one participant cross-posted content from their personal site to social media sites to some degree, referring to this process as , which may be manual or automatic. All participants said they need centralised services in order to reach their social network(s), as they did not expect their friends and family to go out of their way to read their personal website on a regular basis. Participant K had been involved in various open source social network projects, but missed his regular contacts: Participant J agreed that he had looked at some open source projects, but didn't like their because his friends were still using centralised systems and he wants them to read the things he writes.
However, most participants did not simply copy all content to all networks indiscriminately but employed a variety of policies when deciding which posts to syndicate where.
Contents: is the media or data or length of text contained in this post consistent with the type of content generally posted to this site? This could be a cultural constraint, or a technical restriction. Participant M says content must so any inconsistencies from what's expected don't distract from the content itself. Participant E makes collages of photos to post because and F points out the .
Does the content cover a subject appropriate to discuss on the third-party platform? Participant N wouldn't write academic things on Facebook for fear of boring people.
Frequency of posts: Almost 75% of participants were worried about creating undue . For example, only carefully selected photos are generally posted to Instagram, but a whole, uncurated set is uploaded to Flickr.
Who will see it: is the content of the post appropriate for the connections they know they have on the third-party platform? Will the content be distributed publicly or privately on this platform? Is the anticipated level and type of engagement with the content by others desirable?
Participant B uses Medium to reach to people beyond his normal circles of . Participant F withholds certain content from Facebook to avoid social-media-novice family members making unrelated personal comments which all of her other contacts can see. Participant I keeps his social media profiles fully private, even though they mirror the public content posted on his personal site, considering the interactions on Twitter for it to be worthwhile letting strangers comment on his posts.
What will it look like: 70% think about how their content would be rendered on other networks when deciding whether to syndicate there; for example, since short text-only notes look unappealing on Facebook, but images and link previews are presented well, they only syndicate content to Facebook when it includes the latter.
Even when posting primarily on their own website, the importance of the network means that participants are still bound to some extent by the norms and expectations of the communities and platforms used by their friends and contacts. Most participants found more freedom in posting to their own sites with regards to types of posts, content and posting frequency. However those who were more committed to cross-posting, or did not have tooling available to allow them to be selective about cross-posting, were strongly influenced by the other destinations for their content when making posting decisions, in some cases self-censoring their content or amending how it is presented.
(De)compartmentalisation and audience
One third of participants said they do not think about their audience, but seven described how they are very aware of who might be reading their content, including that they revise content until they feel it is appropriate for multiple audiences they imagine might see it. Five people say they primarily post for themselves, and four said that whilst they selectively cross-post subsets of content based on the norms and audience of third-party platforms, they actively want to collapse these contexts on their own site.
Some would consider filtering based on who was looking, if it was technically straightforward. However most don't care at all about audiences from different aspects of their lives coming across their posts, or imagine the audience for their site is so small that context collapse is unlikely. Some people even saw this as positive, describing it as (M, I) or (I). Four acknowledged their privilege as non-vulnerable members of society which allowed them to feel this way.
Despite this, seven participants said they post pseudonymously or anonymously in other systems which are completely disconnected from their primary online identity. This is usually about sensitive topics that they are not willing to share more broadly, and don't trust their own technical expertise to build sufficient access control into their own systems.
Self-expression
Despite the uses for centralised systems in terms of network reach and audience management, one aspect of control desired by participants is how they are able to express themselves.
Self-expression through visuals: Participants cared a lot about what their websites look like. Three quarters said that having creative control over the appearance of their content was one of their main motivations for publishing on their own site. For some, this stemmed from wanting 'clean and simple' visuals as opposed to the 'noisy' interfaces of Facebook and Twitter. For others, it was important that they had freedom to experiment.
Participant L showed other peoples' sites he was inspired by visually, including one which uses a unique design for each individual blog post. Participant N publishes his art on his site — alongside his technical and academic essays — which involves executing code, so he is unable to use existing platforms.
Participant I has archives dating back over a decade, and for many years experimented with a different design every month. These designs are frozen in time, so clicking back through these archives reveals radical changes in visuals which capture moods, ideas and experiments from the time the posts were written:
He was convinced these temporal visuals were by his own memories of blog posts he'd read looking a certain way, and the associations or even nostalgia that come with that when articles are re-discovered. The same participant periodically makes time-limited or post-specific updates to his visual style, and compares this with the way people change their profile pictures on social media to support a particular cause.
When interacting with others in their community, participants may post a message on their own site which triggers a notification to the addressee, who will often display the reply. Despite their strong feelings over how their posts are presented on their own site or on social media, no participants whose replies are displayed on another homegrown site (as opposed to a silo) were concerned with how their message is presented there, so long as the content itself is unchanged. The domain owner is within their rights to display incoming content in their own space however they see fit.
Self-expression through voice: Over half of participants were worried about their self expression being compromised through censorship or not being able to use their own voice. One participant, only recently returned to personal publishing, stopped posting on his own site and on social media for several years after a post about his gay relationship resulted in an unpleasant message from his father. As he became increasingly reclusive online, this started to reflect into his offline life as well, and he withdrew socially. Recently he realised this wasn't healthy and made a concerted effort to become more expressive, more confident in his identity and to be about his experiences as a queer software developer. Following this, he very deliberately intends not to conceal parts of himself going forward. He now finds of the different parts of his life and adds that on your own domain,
Participant L cares deeply about the visuals of his site, but ultimately sees them as something that will change: As a result, he does not display any content created by others:
Self-expression through functionality: 60% of participants appreciate the ability to create types of content that no other social systems allow, and to mix and match the types of content they post all in one place, agreeing with the sentiment: "it's my site I can post whatever I want" (I). 11 participants described things they do with their own systems that they cannot get elsewhere, including adding licenses (L), editing or deleting posts (I, O), posting events or RSVPs (A, I), custom lists, logs or channels (A, E, G, K, L).
Empowerment
Participants varied in how they felt their personal sites empowered them, beyond self-expression. For some it was about ownership. Participant J expressed concern that his generation rarely own things, from cars and houses, to music, and his personal site was a way of claiming something back:
However participant B pointed out that and participant L describes personal data ownership as
75% want a place under their control to be the canonical source of their content; the definitive location for their online persona. Participant I's personal site is entirely public, yet his social media profiles — to where all of his posts are syndicated — are locked down, (You can't retweet private tweets, but the original link could be posted in a new tweet).
Longevity
12 participants expressed the importance of being able to archive their content and data. They wanted copies. If a centralised service disappears or bars their access — something which has happened at some point to every participant — most now have their content and often the context of conversations with others, on their own servers. Participant G
For some, this is also about personal development, reflection, and spotting patterns in their behaviour over time. (B). Participant L thinks we should take a 2000 year view of our digital lives, and that we all have a right to store personal data to benefit future societies.
Ephemerality
In contrast to longevity, seven participants create content with the expectation that it will disappear, and see value in being able to do this, and 4 participants explicitly consider social media to be a place for ephemeral content. , said F, explaining why she posts throwaway or snarky comments to Twitter without bothering to archive them in her own space. Many participants treat Facebook replies and likes the same way: (I). However several participants reported that they would archive certain types of content if they could, but at present the technical barrier is too high, and their priority for doing so is too low.
Consent
Another aspect of control is consent. Many members of the community use common tooling to fetch replies from social media to the syndicated copies of their posts. There are privacy safeguards in the tooling that prevent private or access controlled posts from being exposed publicly, but 4 participants either didn't do this, despite a desire for archives, or expressed misgivings about the fact they were: (B) because most contacts on social media were unaware of the possibility that their content would be copied to somewhere else on the Web; somewhere potentially more likely to be indexed by search engines.
Abuse and surveillance
Participant B once posted something which triggered a flood of reactions from an infamously abusive online community. His tooling automatically pulled these responses from social media through to his personal site. Rather exercising his ability to remove these posts, he Other participants consider themselves lucky not to have experienced this, and give little thought to how they would handle it.
Although 7 participants (N) none expressed concern about centralised systems mining the data they syndicate, or the terms of service they are agreeing to in doing so.
Inspiration and triggers
Almost all participants said they were inspired by others in the community, and other personal sites they see on the Web. Some took specific ideas to do with visuals or the types of content they can post; others were just inspired by the movement towards data ownership in general. Some participants said they replicated features they like from centralised services.
Half of participants said they built new functionality into their systems when their current way of doing something became too painful or inconvenient. Others want to keep up with the trends in the community in general, so they implement new features in order to continue interoperating with others, or just to try things out. Many said they update their systems when they have enough free time to do so, and have long todo lists of things they want to achieve.
Most were triggered to update their bios on both their personal sites and across their social media profiles when something changed in their life. Except for participant O, who updated specifically when he realised he would need to give his URL(s) to someone and didn't want his information to be out of date.
Discussion
The we interviewed revealed their primary motivations in replacing or supplementing mainstream social media with their own personal systems are control of their online representation, and over the longevity (or not) of their content, and decompartmentalising or making a canonical source for all aspects of their online presence.
Across all of the participants there was diversity in both systems used and the main emphases of conversation, however as mentioned previously there were many common threads around audience and control.
Participants who feel over-constrained by the limitations of social media with regards to the kinds of content they can create and how it must be laid out or displayed have developed their own completely custom publishing environments in order to more freely express themselves. They demonstrate many creative ways of displaying types of content similar to that ordinarily found on social media, as well as innovating with new or ways of sharing information that they cannot do elsewhere at all. This freedom to experiment leads them to reflect on and perhaps better understand their identities. Further, participants feel empowered by the ability to archive their content for life, or hide or remove content from their own space as they like.
Participants still wanted to reach their networks on mainstream social platforms, and were influenced by the norms and expectations of these platforms when deciding what to post. A result of this is that the content they post is still influenced by the platforms they know it will end up being seen on. A technique to mitigate the risk of violating norms on other platforms or encountering technical barriers is to be selective when cross-posting. Though there is no hard and fast formula to follow, participants commonly consider audience, visuals, content types, posting frequency, and topics as part of a gut intuition when making these decisions. Thus personal social systems cannot be studied understood in isolation.
Individuals who are preoccupied with their own ability to control their profiles also think about how they interact with the content of others, discussing consent when it comes to re-displaying posts or data belonging to others.
Data ownership for these participants is helped by the use of a single personal platform, and as a result participants need to find new ways to manage audience and context collapse. Several participants actively desired context collapse in their personal systems, to create a complete image of themselves, no matter who is viewing it, even though they segregate their audience across different mainstream platforms, and selectively cross-post accordingly.
Three quarters of participants want to control the authoritative source of their content. Three quarters said that having creative control over their self-expression through appearance of their content is one of the main motivations for publishing on their own site. Participants feel empowered by the ability to archive their content for life, or remove content from their own space as they like (persistence vs. ephemerality). If a third-party service disappears or bars their access most now have their content and often the context of conversations with others, on their own servers.
We can see that the social media makers' prioritisation of the more individualistic aspects of identity management (per blogging) combines with the goals of retaining audience, interaction and network to allow collaborative identity construction (like contemporary social media); perhaps this is the beginnings of a more complete presentation of self online.
Contributions to the 5Cs
What it means to control one's online self-expression was emphasised by this study. A priority of these participants was having the ability to choose whether content is persistently archived or temporary, ephemeral. They also wished to choose where their data shows up (eg. through cross-posting), and expressed concern that others may not have that option (per consent). Another aspect of control is to be the canonical or authoritative source of one's online presence.
Many interviewees cited self-expression as a primary motivation. Their online spaces tended to be highly customisable as a result, in contrast with mainstream SNS.
The isolation of running a personal site was mitigated by hooking into the network of mainstream social media. This demonstrates a novel means of connectivity which shows both a hyper-awareness of audience as well as some degree of disregard for who reads their content from different contexts.
Critically, despite avoidance in principle of centralised social systems, such systems strongly impact the context in which our makers operate. Community norms and technical constraints of alternate platforms influence content and presentational decisions. It is especially pertinent that these individuals may be considering cross-posting something from its source location in their own system to multiple third-party systems at once.